AI项目开发总结-叙事可视化
问题与策略
如何编写 LLM,缺乏经验和技巧、方法论
Prompt Engineering、CoT、结构化等等
LLM 推荐的图表不正确
LLM 输出的 JSON 结构不正确
JSON Mode
后处理
定的很多规则,无法命中
比如动画类型。
之前东明的可视化推荐也是这个问题,搞了很多图表,但是场景无法命中。
LLM 处理耗时很长
前端需要等待很长时间。
而且推荐类的,还不能流式输出展示。
我们这次 3 个 LLM 请求还有依赖关系。
缺乏 LLM 日志的展示页面
而且要考虑 LLM 内容的可读性问题(格式化)。
不同环境的配置和参数的一致性问题
产品调试和开发代码里面的不一致,比如:
模型类型
模型版本日期
temperature 参数
top_k 参数
等等
手动测试效率低
单元测试
AI 工作流平台
Prompt 管理等
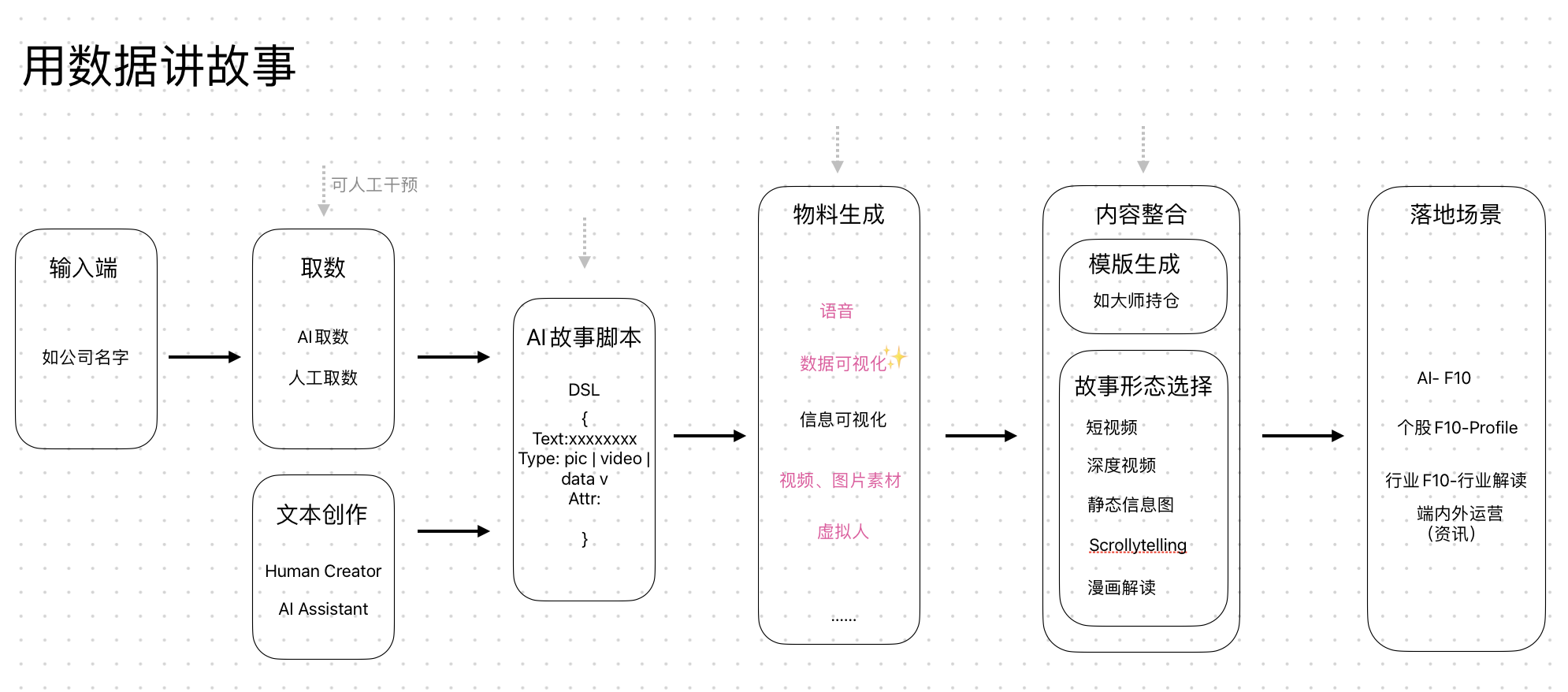
技术拆解
文本生成
data + narration + prompt -> LLM -> text
Prompt:
1 | |
资讯业务
- 取数
- 程序化计算数据特征
- 特征字段名转换为中文
- 根据 Prompt 模板生成文本
- 文本分割(LLM)
- 文本-特征-数据匹配(LLM,图表类型定死了 line)
- 整合结果(text、insight,insight 定死了 animationEffect: ‘PF’, type: ‘LineComparison’)
RAG
structured retrieval
https://docs.llamaindex.ai/en/stable/examples/retrievers/auto_vs_recursive_retriever/
这个就是东明说的那个结构化数据的 index 吧
Store Document Hierarchies (summaries -> raw chunks) + Recursive Retrieval: Embed document summaries and map that to the set of raw chunks for each document. During query-time, do recursive retrieval to first fetch summaries before fetching documents.
复旦发布:最佳 RAG 方案
https://mp.weixin.qq.com/s/0m36A3J9veZzhLSV0ExcWA
训练分类器判断哪些任务需要 RAG
对于完全基于用户提供信息的任务,标记为“足够”,不需要检索;否则,标记为“不足”,可能需要检索。训练了一个分类器来自动化这一决策过程。
三种查询转换方法:查询重写、查询分解和伪文档生成。
查询重写:
通过改写查询以更好地匹配相关文件,提升性能。
查询分解:
基于原始查询中提出的子问题检索文件。
伪文档生成:
根据用户查询生成假设文档,并使用假设答案的嵌入检索类似文件。
待解决的问题
输出的正确性
- RAG
- 给 LLM 减负
输出的稳定性
- 程序化、规则化
- 给 LLM 减负
Insight 类型
- StandardChart 的程序扩展性
- 工作量的问题
未来规划
定位:AIGC 内容创作流程中的可视化图表物料生成工具
当前阶段,我们先专注于数据图表的生成
输入:
输出:
关键:定一个各个物料的接入 DSL
感触
最后的 10%
研究只需要不断提高准确率就行了
但是:商用必须 90%的正确率+一大堆兜底工程策略
兜底的工作量远比想象中大
不可知性
解决了一个问题,又会有新的问题出现,比如:LLM 推荐的图表不正确,解决了之后,又会有新的问题出现,比如:LLM 输出的 JSON 结构不正确。
对于什么时候能搞定,难以定出明确的时间表。
不要让 LLM 处理太多事情
应该是 LLM+RAG+工程化(前处理、后处理)