AIGC名词概念

Model: dreamshaper
Prompt: Futured building complex in cyberpunk style city, terrified crowd,many neon lights,sense of science and technology,vision,masterpiece, high quality, highres, Cinematic level lenses and lighting
问题
发展
https://arxiv.org/pdf/1810.06339.pdf
学习是为了更好地对环境进行探索,而探索是为了获取数据进行更好的学习。
人生中学习亦是如此。
人工智能是目标,是结果,而机器学习是方法,是过程。
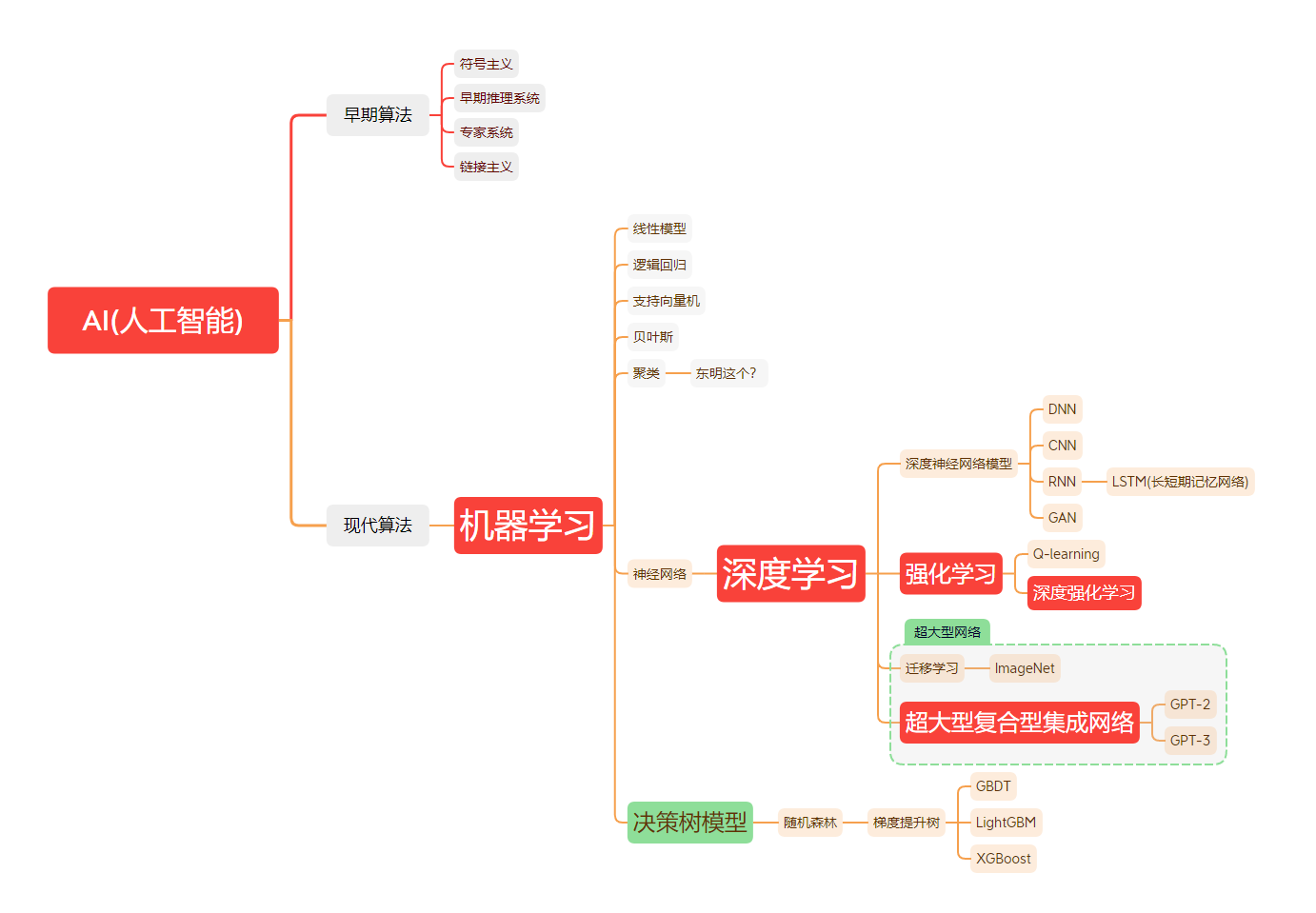
发展历程
内容来自阮一峰的这个文章:
http://www.ruanyifeng.com/blog/2024/12/weekly-issue-330.html
前些日子,我读了李开复老师的两本书:《AI·未来》(浙江人民出版社,2018)和《AI·未来进行式》(浙江人民出版社,2022)。
这两本书都是面向社会大众解释 AI,不是技术类书籍,但是有一些段落,阐述 AI 概念。
李开复老师用通俗的语言来解释,人工智能、机器学习、神经网络、深度学习……这些词到底是什么意思?彼此有什么关系?
我觉得,这些介绍对理解 AI 的体系,挺有启发的。它们分散在各个章节,我将它们整理在一起。
为了行文连贯,我没有完全照搬原文,而是用自己的语言重新叙述,如果有错误,也归咎我。
(1)人工智能
1956 年夏天,计算机科学家约翰·麦卡锡(John McCarthy)首次提出”人工智能”(AI)这个概念。
人工智能指的是,通过软件和硬件,来完成通常需要人类智能才能完成的任务。它的研究对象,就是在机器上模拟人类智能。
(2)机器学习
早期,人工智能研究分成两个阵营。
第一个阵营是规则式(rule-based)方法,又称专家系统(expert systems),指的是人类写好一系列逻辑规则,来教导计算机如何思考。
可想而知,对于复杂的、大规模的现实问题,很难写出完备的、明确的规则。所以,这种方法的进展一直很有限。
第二个阵营就是机器学习(machine learning),指的是没有预置的规则,只是把材料提供给计算机,让机器通过自我学习,自己发现规则,给出结果。
(3)神经网络
神经网络(neural network)是机器学习的一种主要形式。
神经网络就是在机器上模拟人脑的结构,构建类似生物神经元的计算网络来处理信息。
一个计算节点就是一个神经元,大量的计算节点组成网络,进行协同计算。
神经网络需要极大的算力,以及海量的训练材料。以前,这是难以做到的,所以 20 世纪 70 年代开始,就陷入了停滞,长期没有进展。
(4)深度学习
深度学习是神经网络的一种实现方法,在 20 世纪 80 年代由杰弗里·辛顿提出。它让神经网络研究重新复活。
深度学习是一种让多层神经元可以进行有效计算的方法,大大提高了神经网络的性能。”深度学习”这个名字,就是比喻多层神经元的自主学习过程。
多层神经元包括一个输入层和一个输出层,它们之间有很多中间层(又称隐藏层)。以前,计算机算力有限,只能支撑一两个中间层,深度学习使得我们可以构建成千上万个中间层的网络,具有极大的”深度”。
(5)Transformer
早些年,深度学习用到的方法是卷积神经网络(CNN)和循环神经网络(RNN)。
2017 年,谷歌的研究人员发明了一种新的深度学习处理方法,叫做 Transformer(转换器)。
Transformer 不同于以前的方法,不再一个个处理输入的单词,而是一次性处理整个输入,对每个词分配不同的权重。
这种方法直接导致了 2022 年 ChatGPT 和后来无数生成式 AI 模型的诞生,是神经网络和深度学习目前的主流方法。
由于基于 Transformer 的模型需要一次性处理整个输入,所以都有”上下文大小”这个指标,指的是一次可以处理的最大输入。
比如,GPT-4 Turbo 的上下文是 128k 个 Token,相当于一次性读取超过 300 页的文本。上下文越大,模型能够考虑的信息就越多,生成的回答也就越相关和连贯,相应地,所需要的算力也就越多。
几种学习的区别
机器学习:一切通过优化方法挖掘数据中规律的学科。
深度学习:一切运用了神经网络作为参数结构进行优化的机器学习算法。
强化学习:不仅能利用现有数据,还可以通过对环境的探索获得新数据,并利用新数据循环往复地更新迭代现有模型的机器学习算法。学习是为了更好地对环境进行探索,而探索是为了获取数据进行更好的学习。
深度强化学习:一切运用了神经网络作为参数结构进行优化的强化学习算法。
强化学习和有监督学习的学习目标其实是一致的,即在某个数据分布下优化一个分数值的期望。不过,经过后面的分析我们会发现,强化学习和有监督学习的优化途径是不同的。
作者:Xenophon Tony
链接:https://www.zhihu.com/question/279973545/answer/588124593
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
应用方向
| 名称 | 分类 | 关键词 | 应用方向 |
|---|---|---|---|
| 传统机器学习 | lr svm decision tree GBDT RF etc. | 数据挖掘、数据分析和预测 | |
| 深度学习 | 算法 | 有标签、解决感知问题(五官)、静态学习过程 | 图像处理、NLP |
| 强化学习 | 算法 | 智能体(Agent)、环境、奖惩、交互(动态学习过程)、无标签、解决决策问题(大脑) | AI 游戏(如 Atari),推荐系统(如阿里家的),机器人控制相关(如 Ng 的无人机飞行) |
强化学习与深度学习的区别
1、深度学习的训练样本是有标签的,强化学习的训练是没有标签的,它是通过环境给出的奖惩来学习
2、深度学习的学习过程是静态的,强化学习的学习过程是动态的。这里静态与动态的区别在于是否会与环境进行交互,深度学习是给什么样本就学什么,而强化学习是要和环境进行交互,再通过环境给出的奖惩来学习
3、深度学习解决的更多是感知问题,强化学习解决的主要是决策问题。因此有监督学习更像是五官,而强化学习更像大脑。
Andrej Karpathy 在一篇推文中将预训练(pretraining)、监督式微调(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL)比作教科书学习的三个阶段:理论、例题和习题。
具体来说:
预训练阶段类似于教科书中的背景信息和概念阐述,模型通过阅读海量文本学习语言规律和知识,为后续学习打下基础。
监督式微调阶段类似于教科书中的例题及解答,模型通过学习“理想答案”来生成高质量的输出。
强化学习阶段类似于教科书中的练习题,模型通过试错和反馈不断改进。
Karpathy 认为,目前我们已经让模型经历了大量的“阅读”和“学习例题”,但强化学习这一“实践练习”阶段还处于新兴的、尚待开发的阶段。
相关推文的出处可以参考:X.com/karpathy/status/1885026028428681698。
强化学习(RL)和监督微调(SFT)的区别和关系是什么?
强化学习(Reinforcement Learning, RL)和监督微调(Supervised Fine-Tuning, SFT)是两种常见的模型优化方法,尤其在大型语言模型(LLMs)的训练中被广泛应用。它们在目标、训练方式和应用场景上存在显著区别,但也可以结合使用以提升模型性能。以下是它们的区别和关系的详细分析:
区别
1. 目标
- 监督微调(SFT):
- 目标:通过标注数据对预训练模型进行微调,使其更好地适应特定任务或领域。SFT 的目标是让模型学习到标注数据中的模式和规律,从而在新数据上表现更好。
- 应用场景:适用于有大量标注数据的任务,如文本分类、情感分析、问答系统等。
- 强化学习(RL):
- 目标:通过与环境的交互来学习最优策略,以最大化累积奖励。RL 的目标是让模型在动态环境中做出最优决策。
- 应用场景:适用于需要动态决策的任务,如机器人控制、游戏 AI、推荐系统、复杂推理任务等。
2. 训练方式
- 监督微调(SFT):
- 训练数据:需要大量的标注数据(输入-输出对)。这些数据通常由人工标注,用于指导模型学习。
- 学习过程:模型通过最小化预测值和真实值之间的误差(如交叉熵损失)来调整参数。训练过程通常是静态的,数据是预先准备好的。
- 强化学习(RL):
- 训练数据:不需要预先标注的数据,而是通过智能体与环境的交互动态生成数据。智能体根据当前状态采取行动,环境返回奖励和新的状态。
- 学习过程:使用奖励信号来指导学习。智能体通过试错(trial-and-error)来探索环境,逐步学习到最优策略。训练过程是动态的,数据是通过交互实时生成的。
3. 反馈机制
- 监督微调(SFT):
- 反馈:直接提供正确的输出标签,模型通过比较预测值和真实值来调整参数。
- 即时性:反馈是即时的,每次训练时都能直接获得正确的答案。
- 强化学习(RL):
- 反馈:通过奖励信号来提供反馈。奖励信号通常是稀疏的(sparse)和延迟的(delayed),智能体需要通过多次尝试来理解哪些行为是有效的。
- 延迟性:反馈是延迟的,智能体需要在多个时间步后才能评估其行为的长期效果。
4. 模型输出
- 监督微调(SFT):
- 输出:通常是具体的预测值(如分类标签、回归值)。
- 强化学习(RL):
- 输出:是一个策略(policy),即在给定状态下采取的行动。策略可以是确定性的(deterministic)或随机性的(stochastic)。
5. 数据依赖性
- 监督微调(SFT):
- 数据依赖性高:需要大量的标注数据,数据的质量和数量直接影响模型的性能。
- 强化学习(RL):
- 数据依赖性低:不需要大量的标注数据,而是通过智能体与环境的交互动态生成数据。
关系
1. 互补性
- 监督微调(SFT):
- 优势:在有大量标注数据的情况下,SFT 可以快速学习到输入和输出之间的映射关系,适用于静态任务。
- 局限性:需要大量的标注数据,且模型的泛化能力可能受限于训练数据的分布。
- 强化学习(RL):
- 优势:不需要大量的标注数据,可以通过试错学习到最优策略,适用于动态和交互式任务。
- 局限性:学习过程可能较慢,且需要大量的交互来探索环境。
2. 结合使用
- SFT + RL:
- 方法:可以先使用监督微调对模型进行预训练,使其具备一定的初始知识,然后通过强化学习进一步优化模型的性能。例如,在自然语言处理中,可以先使用监督微调训练一个语言模型,再通过强化学习优化其在特定任务(如复杂推理、对话系统)中的表现。
- 案例:在 DeepSeek-R1 中,作者先使用少量冷启动数据进行监督微调,然后通过强化学习进一步提升模型的推理能力。
- RL + SFT:
- 方法:在强化学习过程中,可以使用监督微调来优化奖励模型或价值函数。例如,使用监督微调训练一个价值网络来估计状态的价值,从而指导强化学习的策略优化。
- 案例:在某些复杂任务中,可以先通过强化学习生成高质量的数据,然后使用这些数据进行监督微调,进一步提升模型的性能。
3. 理论联系
- 统一框架:
- 决策理论:监督微调和强化学习都可以从决策理论的角度进行统一描述。监督微调可以看作是一种特殊的强化学习,其中奖励信号是即时且确定的。
- 优化目标:两者都通过优化目标函数来调整模型参数,只是目标函数的形式和优化方式不同。
总结
监督微调(SFT)和强化学习(RL)在目标、训练方式和应用场景上存在显著区别,但它们也可以相互补充,结合使用以解决更复杂的问题。理解它们的区别和关系有助于在实际应用中选择合适的优化方法。
数据格式
SFT
1 | |
基于 DeepSeek 的可视化模型的训练数据格式
2025.02.04:基于 QWen32B 蒸馏的 DeepSeek R1 模型
1 | |
上面的 res 的结构:
1 | |
RL
1 | |
代码实现
强化学习
- 通过与环境的交互来学习最优策略。
- 适用于需要动态决策的任务。
- 通过奖励信号来优化模型的行为。
强化学习通常用于需要动态决策的任务,例如游戏 AI 或复杂推理任务。以下是一个简单的例子,展示如何使用强化学习训练一个语言模型进行数学问题求解。
示例:使用强化学习训练语言模型进行数学问题求解
1 | |
监督微调
- 使用标注数据对模型进行微调。
- 适用于有大量标注数据的任务。
- 通过最小化预测值和真实值之间的误差来优化模型。
监督微调通常用于有标注数据的任务,例如文本分类或问答系统。以下是一个简单的例子,展示如何使用 PyTorch 对一个预训练的语言模型进行监督微调。
示例:使用 Hugging Face Transformers 进行监督微调
1 | |
推理模型与指令模型的区别
1. 推理模型(Reasoning Models)
- 目标:推理模型的目标是解决复杂的逻辑、数学、科学或其他需要多步骤思考的问题。这些模型需要能够生成详细的推理过程(Chain-of-Thought, CoT),并通过逻辑推理得出正确的答案。
- 应用场景:数学问题求解、逻辑推理、科学问题解答等。
- 特点:通常需要模型具备深度思考和多步骤推理的能力,输出结果通常包括推理过程和最终答案。
2. 指令模型(Instruction Models)
- 目标:指令模型的目标是理解和执行用户给出的指令,生成符合用户需求的输出。这些模型需要能够理解自然语言指令,并生成准确、有用的回答。
- 应用场景:文本生成、问答系统、写作辅助、代码生成等。
流程
架构、模型、算法的关系
在机器学习中,架构、模型和算法是三个关键概念,它们之间有一定的区别和联系。
首先,架构通常指整个模型的结构和组织方式,包括各个组件之间的连接方式、层级结构、参数等。例如,在深度学习中,卷积神经网络(CNN)和循环神经网络(RNN)就是两种常见的架构。
其次,模型指的是具体的数学模型或函数,用于描述输入和输出之间的关系。模型可以是线性的,也可以是非线性的,可以是有监督的,也可以是无监督的。模型通常由多个参数组成,这些参数可以通过训练来学习和优化。
最后,算法是指用于训练和优化模型的具体方法和技术,例如梯度下降、随机梯度下降、Adam 等。算法通常是针对特定的模型和问题而设计的,不同的算法可以产生不同的模型和结果。
总的来说,架构、模型和算法是机器学习中不同层次的概念,它们之间有一定的联系和依赖关系,但也有各自的独立性和特点。在实际应用中,我们需要根据具体的问题和数据来选择适合的架构、模型和算法,以达到最优的效果。
架构
在机器学习中,常用的架构包括以下几种:
深度神经网络(Deep Neural Network,DNN):由多个神经网络层组成的模型,可以用于图像、语音、自然语言处理等领域的任务。
卷积神经网络(Convolutional Neural Network,CNN):专门用于图像处理的一种神经网络,通常包括卷积层、池化层和全连接层等组件。
循环神经网络(Recurrent Neural Network,RNN):适用于序列数据的一种神经网络,可以处理时序数据,如语音、文本等。
长短时记忆网络(Long Short-Term Memory,LSTM):一种特殊的循环神经网络,可以处理长序列数据,避免了传统 RNN 中的梯度消失问题。
支持向量机(Support Vector Machine,SVM):一种经典的分类算法,可以用于二分类和多分类任务。
决策树(Decision Tree):一种基于树结构的分类和回归算法,可以用于处理离散和连续型特征。
集成学习(Ensemble Learning):通过组合多个模型的预测结果来提高性能的一种方法,如随机森林、Adaboost 等。
以上是机器学习中常用的一些架构,不同的任务和数据集可能需要不同的模型和算法来解决。
模型
机器学习中常用的模型有很多,以下是其中的一些:
线性回归模型:用于建立输入和输出之间的线性关系,常用于回归问题。
逻辑回归模型:用于建立输入和输出之间的非线性关系,常用于分类问题。
决策树模型:用于将数据集划分为不同的子集,常用于分类和回归问题。
随机森林模型:由多个决策树组成的集成模型,常用于分类和回归问题。
支持向量机模型:用于将数据集映射到高维空间,从而更容易找到分类边界。
神经网络模型:由多个神经元组成的网络,常用于分类和回归问题,尤其是在图像和语音识别等领域。
聚类模型:用于将数据集中的样本分为不同的簇,常用于无监督学习问题。
朴素贝叶斯模型:基于贝叶斯定理,用于计算给定输入的条件下输出的概率,常用于分类问题。
这些模型各有优缺点,具体应用时需要根据数据集和任务的特点选择合适的模型。
文件格式
GGUF
GGUF(GPT-Generated Unified Format)是一种专为大型语言模型(LLM)设计的二进制文件格式,由 llama.cpp 团队开发(原 GGML 格式的升级版)。它主要用于在 CPU 或边缘设备(如手机、嵌入式设备)上高效运行模型推理,尤其适合量化后的模型部署。
算法
机器学习中常用的算法有很多,以下是其中的一些:
监督学习算法:包括分类和回归两种类型。常用的监督学习算法有线性回归、逻辑回归、决策树、随机森林、支持向量机、神经网络等。
无监督学习算法:包括聚类、降维等类型。常用的无监督学习算法有 K-Means、DBSCAN、PCA、t-SNE 等。
半监督学习算法:介于监督学习和无监督学习之间,既利用有标签数据又利用无标签数据。常用的半监督学习算法有自学习、半监督 SVM 等。
强化学习算法:通过智能体与环境的交互来学习最优策略。常用的强化学习算法有 Q-Learning、SARSA、Deep Q-Network 等。
迁移学习算法:通过将已学习的知识迁移到新任务上来提高学习效果。常用的迁移学习算法有领域自适应、多任务学习等。
这些算法各有优缺点,具体应用时需要根据数据集和任务的特点选择合适的算法。
基础概念
机器学习和深度学习的常见任务
在机器学习和深度学习中,常见的任务类型包括分类、回归、聚类、降维和生成等。具体来说:
分类任务:将数据分为不同的类别,常见的应用包括垃圾邮件识别、图像分类、情感分析等。例如,将电子邮件分为垃圾邮件和非垃圾邮件,将图像分为猫、狗、车等不同的类别。
回归任务:预测一个连续的数值,常见的应用包括房价预测、股票价格预测、销售额预测等。例如,预测一栋房子的价格,预测某只股票的价格等。它被称为回归任务是因为这种任务最初被描述为回归到平均值。
聚类任务:将数据分为不同的聚类,常见的应用包括用户分群、市场细分、图像分割等。例如,将用户分为不同的群体,将市场分为不同的细分市场等。
降维任务:将高维数据降低到低维空间,常见的应用包括可视化、特征提取等。例如,将高维图像数据降低到二维或三维空间,以便于可视化和分析。
生成任务:生成新的数据,常见的应用包括图像生成、文本生成等。例如,生成艺术作品、生成新闻报道等。
以上只是一些常见的任务类型和应用案例,实际上机器学习和深度学习的应用非常广泛,涉及的领域也非常多。
bit 和 byte
Bit(比特)是计算机中最小的存储单位,它只能存储 0 或 1 两个值。而 Byte(字节)则是计算机中常用的存储单位,它由 8 个比特组成,可以表示 256 种不同的值(28)。
在计算机中,数据存储和传输的单位通常是字节。例如,一个整数通常由 4 个字节组成,一个字符通常由 1 个字节组成。因此,我们经常听到计算机存储容量的单位是以字节为基础的,如 KB、MB、GB 等。
总的来说,比特是计算机中最基本的单位,而字节则是常用的数据存储和传输单位。
checkpoint
在深度学习中,checkpoint 是指保存模型的一种机制,可以在训练过程中定期保存模型的参数和状态,以便在训练过程中出现错误或需要中断训练时,可以从最近的 checkpoint 继续训练,而不需要从头开始训练。此外,checkpoint 还可以用于在训练结束后评估模型的性能或进行推理。在 TensorFlow 和 PyTorch 等深度学习框架中,都提供了 checkpoint 的相关功能。
评价指标
PPL(Perplexity)
在自然语言处理中,PPL 是指困惑度(Perplexity),它是用来评估一个语言模型的好坏程度的指标。困惑度越低,表示模型越好。PPL 的计算方式是将测试集中的每个句子作为输入,计算模型预测这个句子的概率,然后将这些概率取对数,最后求平均值并取负数。这个值越小,表示模型的预测能力越好。因此,在训练模型时,我们通常会尝试不同的模型架构、超参数等,以获得更低的困惑度,从而提高模型的预测能力。
Top1/Top5 准确率
TOP-1 正确率=(所有测试图片中正确标签包含在前 1 个分类概率中的个数)除以(总的测试图片数)
TOP-5 正确率=(所有测试图片中正确标签包含在前五个分类概率中的个数)除以(总的测试图片数)
https://blog.csdn.net/qq_27278957/article/details/120077439
1 | |
输出结果为:
1 | |
模型训练
zero-shot、one-shot、few-shot
Zero-shot learning 是指在没有针对特定任务进行过训练的情况下,模型可以从未见过的类别中进行预测或分类的能力。通常,传统的机器学习算法需要在训练集中包含所有可能的类别,才能够对这些类别进行分类。但是,zero-shot learning 可以在没有训练数据的情况下,通过利用模型对语言、知识和先验信息的理解,对新类别进行分类或预测。这种技术可以让模型更具有泛化能力,从而可以应对更多的场景和任务。
One-shot learning 是指在只有一个样本的情况下,模型可以对新的类别进行分类或预测。这种技术通常需要使用相似度度量等方法来让模型从一个样本中学习如何进行分类或预测。
Few-shot learning 是指在非常少量的训练数据的情况下,模型可以对新的类别进行分类或预测。这种技术通常需要使用元学习等方法来让模型更好地学习如何从少量的训练数据中进行泛化。
Instruction Turing
指令微调(fine-tuning)
指令微调(fine-tuning)是指使用预训练模型作为初始参数,然后在新的数据集上进行进一步训练的过程。这种方法通常在新的数据集上进行微调,以适应新的任务或数据集。在实践中,通常会固定预训练模型的一部分参数(如底层特征提取器),然后只微调模型的一部分参数(如分类器)。
实施指令微调的步骤通常如下:
- 选择一个预训练模型,通常是在大规模数据集上预训练过的模型,如 BERT、GPT 等。
- 准备新的数据集,包括训练集、验证集和测试集。
- 根据新的任务或数据集,修改预训练模型的最后一层或几层,以适应新的任务或数据集。
- 在新的数据集上进行微调,通常使用随机梯度下降等优化算法来训练模型。
- 使用验证集来调整模型的超参数,如学习率、批大小等。
- 在测试集上评估模型的性能。
需要注意的是,指令微调需要大量的计算资源和训练时间,因此通常需要在 GPU 或分布式系统上进行训练。此外,为了避免过拟合,通常需要使用正则化方法或数据增强等技术来提高模型的泛化能力。
Epoch
在机器学习中,Epoch 是指将整个数据集(数据集可以分为多个批次)完整的过一遍。在训练神经网络时,通常将训练数据分成若干个批次,每个批次包含多个样本。在每个 Epoch 中,神经网络会对每个批次进行一次前向传播和反向传播,更新网络的权重和偏置。Epoch 的数量是一个超参数,需要根据具体情况进行调整。通常情况下,Epoch 越多,模型的训练效果越好,但是也会增加训练时间和计算成本。
指令型训练数据
指令型训练数据是指一类训练数据,其中包含了机器学习模型需要执行的明确指令或任务,以及与之对应的输入和输出数据。这种类型的训练数据通常用于训练基于规则的模型或强化学习模型。
以下是一些指令型训练数据的示例:
机器翻译:给定一句话的源语言文本作为输入,以及对应的目标语言文本作为输出,让模型学会将源语言文本翻译成目标语言文本。
问答系统:给定一组问题和对应的答案,让模型学会根据输入的问题产生正确的答案。
游戏 AI:给定一个游戏环境和一组游戏规则,让模型学会在游戏中执行正确的动作,以达到最优的游戏得分。
语音识别:给定一段语音作为输入,以及对应的文本作为输出,让模型学会将语音转换成正确的文本。
这些示例都是指令型训练数据,因为它们都包含了明确的指令或任务,并且有对应的输入和输出数据。
梯度下降算法
梯度下降算法是一种优化算法,用于训练机器学习模型,特别是深度学习模型。在机器学习中,我们通常需要最小化一个损失函数来获得最优的模型参数。梯度下降算法通过不断地调整模型参数,使得损失函数不断降低,从而达到最小化损失函数的目的。
梯度下降算法的基本思想是:对于当前的模型参数,计算损失函数的梯度(即导数),然后以梯度的相反方向更新模型参数。这样做的原因是,梯度的方向是损失函数增长最快的方向,而我们希望找到损失函数最小的方向,因此需要沿着梯度的相反方向更新模型参数。
梯度下降算法有多种变体,如批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)和小批量梯度下降(Mini-batch Gradient Descent)等。这些变体的主要区别在于每次更新模型参数时使用的样本数量不同,以及更新的频率不同。
step
在模型训练中,一个 step 通常指的是模型在训练过程中进行一次前向传播和反向传播的过程。具体来说,一个 step 中包含以下几个步骤:
将一个 batch 的数据输入到模型中进行前向传播,得到模型的输出。
根据模型输出和标签计算损失函数。
将损失函数反向传播回模型中,计算梯度。
根据梯度更新模型参数。
在训练过程中,每一个 step 都会更新模型的参数,使得模型的预测结果更加准确。通常情况下,一个 epoch 包含多个 step,一个 epoch 结束后,模型会对所有的训练数据进行了一次训练。
超参数(Hyperparameters)
在机器学习中,超参数(Hyperparameters)是指在模型训练之前需要手动设置的参数,这些参数不能通过模型训练过程进行学习,而是需要手动调整。超参数的设置直接影响到模型的性能和训练效果。
常见的超参数包括学习率、批量大小、迭代次数、正则化参数等。这些超参数的设置往往需要经验和实验来进行调整,以获得最佳的模型性能。
超参数的选择通常是一个迭代的过程。首先,我们需要选择一组超参数作为初始值,然后在训练集上训练模型,并在验证集上评估模型的性能。根据验证集的结果,我们可以调整超参数的值,重新训练模型,并再次在验证集上评估模型的性能。这个过程可以一直进行下去,直到我们找到最佳的超参数组合为止。
总之,超参数的选择对于机器学习模型的性能和训练效果至关重要,需要进行仔细的调整和实验。
权重(weights)和偏置(biases)
权重(weights)和偏置(biases)是神经网络中的两个重要的参数。权重是指输入层和隐藏层之间、隐藏层和输出层之间的连接权重,它决定了输入信号在神经网络中的传递方式和强度;偏置是指每个神经元的阈值,它决定了神经元的激活函数的输出值。
在神经网络的训练过程中,我们需要不断地调整权重和偏置,以使得网络的输出与实际值尽可能接近。这个过程叫做反向传播算法(backpropagation),它利用链式法则(chain rule)计算出每个参数对损失函数的影响,从而更新参数。在反向传播算法中,权重和偏置的更新量取决于学习率、梯度和损失函数的形式。因此,权重和偏置是神经网络中非常关键的参数,需要经过精心的调整才能得到最优的结果。
灾难性遗忘(Catastrophic Forgetting)
灾难性遗忘(Catastrophic Forgetting)是指在神经网络模型的连续训练过程中,由于新的数据和任务的引入,导致模型在学习新任务时忘记了之前学习的任务的能力。这种现象通常会导致模型的性能急剧下降,甚至无法完成之前已经学习的任务。
在深度学习中,模型的参数通常是通过反向传播算法进行更新的。当模型接收到新的数据和任务时,它会尝试通过反向传播算法来更新参数以适应新的任务。然而,这种更新会导致模型忘记之前学习的任务,因为新的参数可能会覆盖旧的参数,从而导致旧任务的性能下降。
为了解决灾难性遗忘问题,研究者们提出了许多方法,包括正则化、增量学习、记忆增强等。其中,记忆增强方法是一种常见的方法,它通过在模型中引入额外的记忆单元来存储先前学习的知识,并在新任务中使用这些记忆单元来辅助学习。这种方法可以有效地缓解灾难性遗忘问题,使得模型能够在学习新任务的同时保留之前学习的知识。
特征和 label
在机器学习模型训练中,label 通常指的是训练数据中的目标变量或标签。目标变量是我们希望模型预测的值,也就是训练数据中我们已知的正确答案。在监督学习中,我们通常会将训练数据划分为特征和目标变量两部分,其中特征是用来描述数据的属性或特征,目标变量是我们希望模型预测的值。
例如,在一个二分类问题中,我们可能有一些数据点,每个数据点都有一些特征,比如身高、体重、年龄等等,以及一个目标变量,比如是否患有某种疾病。在这个例子中,我们的目标是根据这些特征预测一个人是否患有疾病,因此目标变量就是标签。
在模型训练过程中,我们会将训练数据的特征和标签作为输入来训练模型,目标是让模型能够根据特征预测出正确的标签。在训练完成后,我们可以使用测试数据来评估模型的性能,以确定模型是否能够泛化到新的数据。
Pad Token
In the context of natural language processing (NLP), a “pad token” (or “padding token”) is used to fill up sequences of words or tokens to a fixed length.
Here’s why this is necessary: When training neural networks, we typically need our inputs to be in the form of equally sized batches. But sentences in a natural language dataset can have varying lengths. To handle this, we add pad tokens to shorter sentences until they match the length of the longest sentence in the batch.
For example, if our batch size is 3, and we have the following sentences:
- “I love dogs.”
- “Cats are great pets.”
- “Birds can fly.”
First, we tokenize the sentences to get:
- [“I”, “love”, “dogs”]
- [“Cats”, “are”, “great”, “pets”]
- [“Birds”, “can”, “fly”]
The second sentence is the longest, with 4 tokens. So, we add a pad token (often denoted as “
- [“I”, “love”, “dogs”, “
“] - [“Cats”, “are”, “great”, “pets”]
- [“Birds”, “can”, “fly”, “
“]
Now, all of our sentences have the same length, and we can input them into our model as one batch.
It’s also important to note that pad tokens don’t contribute to the model’s learning. They are typically masked or ignored by the model during the training process.
LoRA
这个视频的 3 分 40 秒:
https://www.bilibili.com/video/BV1MH4y1g77V/
名词概念
硬件&软件
CUDA
CUDA Compatibility :: NVIDIA Data Center GPU Driver Documentation
CUDA(Compute Unified Device Architecture)是 NVIDIA 公司推出的一种并行计算平台和编程模型,它允许软件开发人员使用 C/C++语言对 NVIDIA GPU 上的并行计算进行编程。CUDA 底层实现了一套自己的指令集架构,通过集成了 NVIDIA 的编译器,可以将 CUDA 代码直接编译成 GPU 可执行代码。
NVIDIA 驱动则是 NVIDIA 公司为其 GPU 提供的驱动程序。GPU 上运行的 CUDA 程序需要安装并正确配置适当版本的 NVIDIA 驱动程序才能运行。在 CUDA 编程过程中,我们需要安装适当版本的 NVIDIA 驱动、CUDA 工具包和 CUDA 示例驱动程序等,以确保 CUDA 程序的运行环境正确设置。
因此,CUDA 和 NVIDIA 驱动之间是密切相关的,两者需要共同配合实现 GPU 的并行计算能力。CUDA 是一种并行计算平台和编程模型,NVIDIA 驱动为 GPU 提供驱动程序和支持,同时需要安装适当版本的 NVIDIA 驱动程序,才能正确运行 CUDA 程序。
Transform 算法架构
ChatGPT 所用的 Transform 算法架构,来自 Google 发表的论文。
https://zhuanlan.zhihu.com/p/48508221
Transformer 是一种用于序列到序列(Sequence-to-Sequence)学习的神经网络模型,于 2017 年由 Google 团队在《Attention Is All You Need》一文中提出。Transformer 完全基于注意力机制(attention mechanism)来计算输入和输出之间的依赖关系,且不需要使用传统的循环神经网络(RNN)或卷积神经网络(CNN),显著提高了训练速度和效率。
Transformer 主要由编码器(Encoder)和解码器(Decoder)组成,编码器将输入序列转换为高维连续向量表示,解码器则将向量表示映射回目标序列,从而实现序列到序列的转换。在计算过程中,Transformer 使用了多头自注意力机制(Multi-Head Self-Attention),它能够对每个输入位置同时关注输入序列的其他位置,从而捕获输入序列的全局信息。此外,Transformer 利用残差连接(Residual Connection)和层归一化(Layer Normalization)技术来加速模型收敛,使其具有更好的性能和可扩展性。
Transformer 模型可以应用于各种任务,包括机器翻译、语言生成、问答系统等 NLP 领域的任务,也可以应用于计算机视觉领域的任务,如图像描述、视频处理等。Transformer 模型的出现,极大推进了序列到序列问题的解决,因此被广泛应用于自然语言处理和其他领域的任务中。
视频介绍:
The Narrated Transformer Language Model - YouTube
seq2seq
Seq2seq,全称为 Sequence-to-Sequence 模型,是由 Google 在 2014 年提出来的一种深度学习模型,用于解决传统的机器翻译等 NLP 任务中输入和输出序列长短不一、上下文语境信息重要等问题。Seq2seq 模型由两个重要部分组成:编码器和解码器。
编码器接受输入序列并将其转化为一个固定长度的上下文向量(Context Vector),该向量包含了整个输入序列的信息;解码器则将该向量作为其初始状态,再根据该向量和之前的输出序列生成下一个输出字符,直至输出序列结束。这样,Seq2seq 模型一方面可以克服输入和输出序列长度不一的限制,另一方面又能够考虑整个序列的语义信息,从而实现更加有效地自然语言生成和处理。
Seq2seq 目前已广泛应用于机器翻译、对话生成、语音识别、图像描述等领域,在机器智能化方面取得了非常显著的成果,是机器翻译领域的核心技术之一。
CNN
CNN 是 Convolutional Neural Network 的缩写,中文叫做卷积神经网络。它是深度学习中广泛应用于计算机视觉、图像处理等领域的一种神经网络架构,特别擅长于处理二维形式的数据,如图像、矩阵等。
CNN 的核心思想是通过卷积操作和池化操作来提取图像等数据的特征,并通过这些特征来进行分类、检测、分割等任务。具体来说,在卷积层中,CNN 通过不断滑动一个卷积核(Filter)在输入图像上进行卷积计算,以提取图像中的特征。随后,通过激活函数对计算结果进行非线性映射,再利用池化层来对特征进行压缩和降采样,以达到提取有效特征并减少计算量的目的。最后,将所有特征汇总到全连接层中,并进行分类、回归等任务。
CNN 广泛应用于计算机视觉领域中的很多经典问题,如图像分类、目标检测、风格迁移、人脸识别等,成为机器智能领域的重要技术之一。
RNN
RNN 是 Recurrent Neural Network 的缩写,中文叫做循环神经网络。它是一种广泛应用于序列数据处理领域的神经网络结构,被用于文本、语音、图像等领域。
RNN 的核心思想是引入时间循环来处理序列数据,即在神经网络内部引入时间概念,以便网络能够记忆之前时刻的输入,并且将其与当前时刻的输入一起作为网络的输入进行计算。这种时间循环的设计可以允许神经网络处理输入之间的长期依赖关系,从而更好地对序列数据进行建模和预测。
RNN 的结构通常由一个或多个循环神经网络单元(RNN Unit)组成,每个 RNN Unit 都会接受上一时刻的输出和当前时刻的输入,并且输出当前时刻的结果和当前时刻的状态,用于下一时刻的计算。这种设计可以使 RNN 网络之间建立长期的联系,比如可以将之前输入字符编码为一个状态,然后利用这个状态和当前输入字符来预测下一个字符。
RNN 的应用是非常广泛的,它被广泛应用于文本生成、语音识别、机器翻译、股价预测、手写体识别、音乐生成等众多领域,并且在自然语言处理领域中占有非常重要的地位。
Attention
https://zhuanlan.zhihu.com/p/311156298
https://zhuanlan.zhihu.com/p/410776234
BERT 模型
https://zhuanlan.zhihu.com/p/103226488
BERT(Bidirectional Encoder Representations from Transformers) 是一个语言表示模型(language representation model)。它的主要模型结构是 trasnformer 的 encoder 堆叠而成,它其实是一个 2 阶段的框架,分别是 pretraining,以及在各个具体任务上进行 finetuning。 pretaining 阶段需要大量的数据,以及大量的计算机资源,所以 google开源了多国的语言预训练模型,我们可以直接在这个基础上进行 finetune。
NLP 领域模型的发展时间线
BERT 和 Transformer 是自然语言处理领域的两个重要技术,它们的发展时间线如下:
- 2017 年,Google 提出了 Transformer 模型,该模型使用自注意力机制实现了在序列到序列任务中的优异表现。
- 2018 年,Google 提出了 BERT(Bidirectional Encoder Representations from Transformers),该模型使用 Transformer 编码器实现了双向预训练,并在多项自然语言处理任务中创下了最好的表现。
- 2019 年,BERT 的改进模型 XLNet 提出,该模型使用了一种新的自注意力机制,称为“Permutation Language Modeling”,在多项任务上取得了更好的表现。
- 同年,Facebook 提出了 RoBERTa,该模型对 BERT 进行了改进,通过更长时间的预训练和更大的数据集,进一步提高了性能。
- 2020 年,Google 提出了T5 模型,该模型使用了 Transformer 编码器和解码器,实现了在多项自然语言处理任务中的优异表现。
- 同年,OpenAI 提出了GPT-3 模型,该模型使用了更大的 Transformer 模型,在多项任务上取得了惊人的表现,引起了广泛的关注和讨论。
总的来说,Transformer 和 BERT 的发展时间线非常紧密相连,它们的发展推动了自然语言处理领域的快速发展。
ViT-Vision Transformer
ViT 是一种基于注意力机制的视觉表示学习方法,全称为 Vision Transformer。它是一种将图像转换为向量表示的方法,可以用于图像分类、目标检测等任务。ViT 的核心思想是将输入的图像分割成多个小块,然后将这些小块转换为向量表示,并将这些向量输入到 Transformer 模型中进行处理,最终得到整个图像的向量表示。
ViT 的优点在于可以将图像转换为向量表示,使得图像处理和自然语言处理等领域可以进行更深入的结合和交叉应用。同时,ViT 还可以通过预训练的方式进行学习,从而提高模型的泛化能力和效果。
不过,ViT 在处理大尺寸图像时可能会面临一些挑战,比如计算复杂度和内存消耗等问题。此外,ViT 也需要大量的数据进行训练,否则可能会出现过拟合等问题。因此,在实际应用中需要根据具体情况进行调整和优化。
参数
那么,什么是参数呢?
按照我粗浅的理解,参数相当于模型预测时,所依据的神经网络的节点数量。参数越多,就代表了模型所考虑的各种可能性越多,计算量越大,效果越好。
既然参数越多越好,那么参数会无限增长吗?
答案是不会的,因为参数受到训练材料的制约。必需有足够的训练材料,才能计算出这些参数,如果参数无限增长,训练材料势必也要无限增长。
我看到的一种说法是,训练材料至少应该是参数的 10 倍。举例来说,一个区分猫照片和狗照片的模型,假定有 1,000 个参数,那么至少应该用 10,000 张图片来训练。
ChatGPT 有 1750 亿个参数,那么训练材料最好不少于 17500 亿个词元(token)。”词元”就是各种单词和符号,以小说《红楼梦》为例,它有 788,451 字,就算 100 万个词元。那么, ChatGPT 的训练材料相当于 175 万本《红楼梦》。
根据报道,ChatGPT 实际上用了 570 GB 的训练材料,来自维基百科、互联网图书馆、Reddit 论坛、推特等等。
Tensor
张量(Tensor)是一种多维数组,是数学和物理领域中的一个重要概念。在机器学习和深度学习中,张量通常指代多维数组,是处理和存储数据的基本单位。张量的秩表示张量的维度数量,而每个轴的长度则表示该维度所对应的元素数量。例如,一个二阶张量可以看作是一个矩阵,拥有两个轴,每个轴上的长度分别表示该维度上所包含的元素数量。
TensorFlow
TensorFlow 名称的由来源于其基础概念——张量。张量是 数学和物理学 中的一个重要概念,它是多维数组的泛化,TensorFlow 就是基于张量计算的一个开源软件库。Tensorflow 这个名字中的 Tensor 就是指张量,Flow 则表示数据流计算模型。
ChatGPT
Chat Generative Pre-trained Transformer
聊天-生成型-预训练-变换-模型
如何提升 LLM 在某个(组)特定任务上的性能
Embedding
在机器学习中,embedding 是一种将高维稀疏数据映射到低维稠密空间的方法。其中最常见的应用是在自然语言处理(NLP)领域,利用 embedding 将文本语言中的单词映射到连续的向量空间中。这样每个单词就可以用一个固定长度的向量来表示,方便机器学习算法进行处理。此外,embedding 的应用也可以扩展到图像处理和推荐系统等领域中。它的核心思想是通过学习将输入数据嵌入到低维向量空间中,从而找到输入数据之间的相似性和差异性,以便更好地对输入数据进行分类、聚类等操作。
Embedding 和 Prompt Engineering 的区别是什么?
Embedding 和 Prompt Engineering 是两种不同的技术。
Embedding 是一种将离散的符号(比如单词或者类别等)映射到连续的向量空间的技术。嵌入(embedding)通常可以使用神经网络来学习得到,它可以将原始的高维符号转化为低维的连续向量表示,并且保持了符号之间的关系,使得它们在向量空间中的距离可以反映出它们之间的语义相似度。嵌入通常用于自然语言处理和推荐系统等应用中。
Prompt Engineering 则是一种目前在自然语言处理领域广泛应用的技术,与 Embedding 不同,它并没有将符号映射到连续的向量空间,而是通过设计合适的提示文本(Prompt)来调整模型的输出,以达到所需的效果。在这种技术中,模型通常使用连续的向量表示,但是这些向量是针对特定任务进行训练的,而不是作为嵌入向量来表示符号。
因此,Embedding 强调的是符号到连续向量之间的转换,而 Prompt Engineering 强调的是调整模型输出的方式。 当处理文本数据时,这两种技术可能会一起使用,即使用嵌入方式将单词映射到向量空间中,然后将这些向量与设计良好的提示文本(Prompt)相结合来训练模型,并调整输出结果。
Prompt Tuning
Prompt Tuning 是一种基于人类提示(prompt)的语言模型预训练技术。与传统的语言模型预训练技术不同,Prompt Tuning 通过将人类提示(通常是一个简短的提示语句)与目标文本相关联,来训练语言模型。在预测时,模型将输入的提示作为条件来生成文本,而不是完全从头开始生成。
使用 Prompt Tuning 预训练的模型可以用于各种自然语言处理任务,如文本分类、命名实体识别、机器翻译等。相比于其他预训练模型,Prompt Tuning 对于小数据集的效果更佳,并且由于使用了人类提示,所以更容易被人类理解和解释。
Prompt Tuning 技术最近得到了广泛的关注和研究,在自然语言生成和对话建模领域中有着广泛的应用前景。
Embedding 和 Prompt Tuning 的区别是什么?
Embedding 和 Prompt Tuning 都是自然语言处理中语言模型预训练的技术,但它们的主要区别在于预训练的目标和方法不同。
Embedding 是一种将文本转化为向量表示的技术。在预训练阶段,模型学习将单词或短语映射到一个向量空间中,同时优化语言模型的下游任务,如情感分析、文本分类、问答等。在推理阶段,模型使用这些向量来表示文本,并将预测任务转化为向量空间内的计算。
与之相比,Prompt Tuning 是一种基于人类模板的文本生成技术。在预训练阶段,模型学习将人类模板(即带有提示的自然语言文本)和相应的目标文本匹配。在推理阶段,模型使用这些人类模板来生成文本,而不是从头开始生成。
因此,Embedding 与 Prompt Tuning 的区别在于,前者是基于向量表示的语言模型,后者则是基于人类模板的文本生成技术。
LoRA
Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,是一种 PEFT(参数高效性微调方法),这是微软的研究人员为了解决大语言模型微调而开发的一项技术。当然除了 LoRA,参数高效性微调方法中实现最简单的方法还是Prompt tuning,固定模型前馈层参数,仅仅更新部分embedding 参数即可实现低成本微调大模型,建议可从 Prompt tuning 开始学起。
LoRA 的基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅 finetune 的成本显著下降,还能获得和全模型微调类似的效果。
https://zhuanlan.zhihu.com/p/620552131
https://zhuanlan.zhihu.com/p/623543497
LoRA 和 Prompt Engineering 的区别是什么?
LoRA 和 Prompt Engineering 是两种不同的深度学习模型优化技术。
LoRA(Learned Optimizer with Recurrent Attention)是由谷歌开发的一种深度学习模型自动优化技术。LoRA 引入了一个可学习的优化器,利用循环神经网络(RNN)构建递增的模型表示来实现自动调参,从而使得深度学习模型的性能提高。
Prompt Engineering(Prompt 编写)则是一种目前在自然语言处理领域广泛应用的技术,与 LoRA 不同,它并没有优化深度学习模型本身,而是通过设计适当的提示(Prompt)来调整模型输出,使其更符合预期。Prompt Engineering 通常用于 NLP 任务,例如文本分类和语言生成,可通过一些诸如生成对抗网络(GAN)等技术实现。
因此,LoRA 是一种优化深度学习模型自身的技术,而 Prompt Engineering 则是一种根据需求调整模型输出的技术。
LangChain
Announcing our $10M seed round led by Benchmark
GitHub - hwchase17/langchain: ⚡ Building applications with LLMs through composability ⚡
https://www.zhihu.com/people/liu-ao-28-51/posts
随着 ChatGPT 等大型语言模型(LLM)的发布,应用开发者越来越倾向于将 LLM 集成到自己的应用中。然而,由于 LLM 生成结果的不确定性和不准确性,目前还无法仅依靠 LLM 提供智能化服务。因此,LangChain 应运而生,其主要目标是将 LLM 与开发者现有的知识和系统相结合,以提供更智能化的服务。
LangChain 是一个开源的应用开发框架,目前支持 Python 和 TypeScript 两种编程语言。它赋予 LLM 两大核心能力:数据感知,将语言模型与其他数据源相连接;代理能力,允许语言模型与其环境互动。LangChain 的主要应用场景包括个人助手、基于文档的问答、聊天机器人、查询表格数据、代码分析等。
目前,LangChain 已获得 1000 万美元的种子轮融资。他们接下来将主要解决以下问题:
- 完善 TypeScript 相较于 Python 的功能差距,使更多的全栈和前端开发者能创建基于 LLM 应用程序;
- 开发若干输出解析器,以便更安全且格式化地处理 LLM 返回的文本;
- 引入 Retriever 抽象,实现更复杂且必要的文档检索类型;
- 与 Weights&Biases、AIM、ClearML 等解决方案集成,提高 LLM 应用程序的可观察性和实验性。
AIGC
AI Generated Content
代表性的作品:
ChatGPT
DALL-E 等从文字生成图像的产品
它们的基础能力是根据一串输入(prompt),生成各种内容并输出。本质上来说,所有的软件系统,都是根据输入,生成输出。所以理论上来说,只要 AI 的能力足够强,是可以完成目前计算机能处理的所有任务的。只不过要从效果和成本两个维度看用 AI 还是传统方法更合适。
评价效果的分水岭,是我们把 AI 的输出当建议,还是当决策。
我们让 ChatGPT 写文章,但不会让它直接把文章发出去,而是一定要看过、改过再发。这就是把 AI 的输出当建议。
自动驾驶,该加速还是减速,该怎么转向,都是 AI 做出决定,并立即执行。这就是决策。
LLMs(大模型)
ChatGPT 用的方法叫「大型语言模型(Large Language Models)」,简称 LLMs。中文习惯称为「大模型」。
简单说,它的思路就是把尽可能大量大量大量大量的数据通过Transformer 架构做机器学习,就能从数据中学到很多很多很多很多能力,多到超出原始设计者的想象。
比方说,它在翻译方面的能力,不输于,甚至超过了专业的机器翻译系统。
AGI
通用人工智能(Artificial General Intelligence,简称 AGI)
以前的 AI,不是 AGI,是因为它们的模型只能做一件事。人脸识别的就是识别人脸,缺陷检测的就是检测缺陷(且只能检测一种缺陷,换了缺陷就得换模型)。AlphaGo 只会下围棋,换成五子棋就会被我狂虐。
而 ChatGPT 已经能够触类旁通,把从 A 学到的能力,用在 B、C、D、E、F 上。
多模态大模型
延续 ChatGPT 的一个研究热点是多模态大模型。简单理解,就是把语音、图像、视频等等各种类型的数据都灌进去,看能否用一个模型解决所有媒体的 AI 生成问题。
LLaMA
Language Learning and Multimodal Applications(语言学习与多模态应用)
Language Learning and Multimodal Applications(LLaMA)指的是应用自然语言处理技术和多模态数据(如语音、图像、视频等)来实现更高效、自然、个性化的语言学习和交流的研究领域。随着深度学习和大数据技术的发展,自然语言处理和多模态数据处理技术已经取得了很多进展,这些技术不仅可以用来实现机器翻译、文本分类、信息检索等功能,还可以应用到语言学习领域,例如:
开发语音识别和自然语言理解技术,使得机器可以理解人类的语音和语言输入,更加接近人类自然交流的方式。
将多模态数据(如图像、视频)与自然语言处理技术结合,实现更加丰富和生动的语言学习和练习体验,例如用图像或视频帮助学习者更好地理解和记忆语言知识。
实现个性化和自适应语言学习,基于学习者的兴趣、学习历史、学习行为等因素,精准地推荐学习内容和学习路径。
LLaMA 是一个跨学科的研究领域,涉及语言学、计算机科学、心理学等多个学科。
NLI
自然语言界面(Natural Language Interface,简称 NLI)
举个例子,我对 Siri 说:「我得新冠了」。Siri 把这句话广播给手机上的所有 App。于是,大家开始各自干活:
Apple Watch 打开了 24 小时血氧监测模式
米家 App 让空调提高温度,并询问我是否马上躺下休息,它可以关闭灯光和窗帘
饿了么建议我吃清淡食物,并推荐几款粥做明天的早餐,让我选择、预订
叮当买药推荐了附近能最快速度送到的退烧药,问我是否下单
猫眼电影建议我取消后天的电影票
Keep 通知我已取消未来一个月内预约的所有操课,还暂停了所有打卡
钉钉帮我起草了病假申请
微信问我要不要发个朋友圈?
当 NLI 成为事实标准,那么互联网上软件、服务的互通性会大幅提升,不再受各种协议、接口的限制。
比如现在华为、阿里、腾讯等都在争抢的物联网操作系统,表面看好像是在做内核,其实本质上是想成为最重要的那个万物互联的协议。
万物想要互联,大家首先要遵守同一个协议。谁的协议成为主流,谁就拥有了最高的话语权。
兼容多种协议,对厂商来说要增加很多成本。如果不兼容,就变成了所支持协议的附属。如果有个通用协议,就好了。
自然语言就是最好的通用协议,谁都可以兼容,谁都无法控制。甚至,说汉语、英语、爪哇语等任何语言都行。
在实现层面,NLI 的接口能极致简单。看看 ChatGPT 的 API 就知道了。
强大如 ChatGPT,无所不知,无所不晓,却只有一个接口函数(https://beta.openai.com/docs/api-reference/completions),16 个参数。
16 个参数里,最重要的只两个:model 和 prompt。其余的都是对生成结果的细节做控制,比较低频。
Model 是选择调用哪个模型。不同模型能力有所不同,价格也不同。
Prompt 是最核心的参数。它就是你在 ChatGPT 聊天框里输入的内容。完全自然语言,想怎么写都行。
所以,NLI 可以极简到甚至只有一个 prompt 参数,就能让所有软件系统形成协作。所有复杂的细节,都被处理 prompt 的 AI 解决了。
人与人,人与机器,机器与机器,都实现了无限制的交流。
为了支持 NLI,所有软件系统都必须集成一个 AI,以 AI 为总控来处理输入,生成输出。这就是 AGI 对信息技术领域带来的革命性变化。
其实相关的研究早就已经开展。在面向对象(Object-Oriented)之后,就有人提出面向智能体(Agent-Oriented)的概念,认为多智能体自治是未来构造软件的主要架构。可惜,当时没有人知道「智能」在哪里。20 多年后,这项研究可以落地了。
ANN
ANN 是人工神经网络(Artificial Neural Network)的缩写,它是一种模拟人类神经系统进行信息处理的数学模型。神经网络由大量非线性处理单元(神经元)组成,这些神经元通过连接强度(权重)来实现信息处理和传递。
ANN 中的神经元类似于人脑中的神经元,它们可以接收输入信号,并根据输入信号和权重计算输出信号。通常,输入信号经过一系列的线性或非线性变换后,将产生一个输出结果,从而完成某种信息处理或分类任务。ANN 可以在无需显式地编程情况下自动学习,并通过多层神经元来实现更加复杂的分类和回归任务。
ANN 广泛应用于图像识别、语音识别、自然语言处理、机器翻译、医疗诊断等领域。例如,卷积神经网络(Convolutional Neural Network,CNN)可以处理图像和视频数据,循环神经网络(Recurrent Neural Network,RNN)可以处理序列数据,深度神经网络(Deep Neural Network,DNN)可以提高模型的精度和鲁棒性。
需要注意的是,ANN 虽然被广泛应用于数据处理、模式识别等领域,但是它也存在许多不足之处,例如容易出现过拟合、泛化能力不足、训练速度慢等问题。因此,在使用 ANN 时,需要结合具体应用场景进行合理的设计和调整。
卷积
卷积是一种数学运算,它常用于信号处理和图像处理等领域。在信号处理中,卷积是通过将一个信号和滤波器进行操作得到的新信号。在图像处理中,卷积是通过将一张图像与一个卷积核进行操作得到的新图像。
在离散情况下,二维卷积通常表示为两个输入矩阵(如图像矩阵和过滤器矩阵)之间按元素相乘、相加所得的输出矩阵。这个计算过程可以通过对图像的每个局部区域应用过滤器来完成,也就是将过滤器作为窗口,沿着图像平面移动并计算输入图像和过滤器的点积,最终得到一个新的特征图。这个特征图可以进一步传入其他神经网络层进行后续处理,例如池化或非线性转换等操作。
卷积核可以根据应用需求指定不同的大小和形状,通常选择 3×3、5×5 或 7×7 这样的小型方形矩阵。卷积操作能够保持原始数据类型的空间信息,同时压缩高维数据,减少存储和计算量,在深度学习模型中被广泛应用于图像处理、语音识别、文本分类等领域。
卷积运算是数字信号处理中一种经典的数学方法,通过将两个函数(通常为一个信号和一个滤波器)进行卷积操作来创建新的输出函数。在机器学习领域,卷积运算也广泛用于图像处理、语音识别等领域。
在卷积操作中,通常使用小的固定大小的矩阵(称为卷积核或卷积滤波器)对一个输入图像或序列进行滑动窗口计算。在这个过程中,卷积核与输入数据逐元素相乘,并对结果进行求和,产生输出值。这个过程会在输入数据上扫描多次,以生成最终输出数据。
卷积运算具有平移不变性,即同一个卷积核可以同时应用于输入图像中不同位置的局部区域,从而实现了对视觉特征的可共享性和可检测性。此外,卷积运算还能够有效地减少参数数量和计算量,提高模型效率,因此被广泛应用于图像识别、目标检测、语音处理等领域,成为深度学习模型中经典的核心计算方式之一。
处理流程
原始数据(比如图片?)-卷积-特征图-池化
卷积的作用是什么
卷积是卷积神经网络中的一种基本计算操作,它的作用是在输入数据上通过可学习的卷积核进行滑动窗口计算,并生成输出特征图。卷积的作用可以归纳如下:
特征提取:卷积操作可以对输入数据进行局部感知并提取局部特征,对于图片而言,卷积核可以检测图像中的不同边缘、线条、纹理等特征。这些特征可以通过多个卷积核的组合来提高其抽象性和稳定性,并进一步表达更高层次的语义信息。
参数共享:卷积核具有参数共享的属性,即一个卷积核在与不同区域进行卷积时使用相同的权重值,使得模型中所需的参数大大降低,避免了模型参数过拟合的问题。
稀疏连接:卷积只考虑局部连接的权值,采用稀疏连接的方式,避免了全连接计算带来的运算量增大,减轻了模型的复杂度和训练难度。
平移不变性:卷积神经网络的卷积操作具有平移不变性,即在输入数据中对位置的改变不会导致输出随之改变,使得模型在处理相同对象的不同位置时具有一定的鲁棒性。
综上所述,卷积对于图像处理和计算机视觉任务非常重要,在卷积神经网络中起到了构建特征图、从数据中提取高层次语义信息、提高网络效率和鲁棒性等重要作用。
卷积核
卷积核(Convolution kernel)也称为滤波器(Filter),是在图像处理和计算机视觉中应用广泛的一种矩阵。卷积核通常是一个小的、固定大小的矩阵,它定义了如何对输入数据进行卷积运算。
在卷积神经网络中,卷积核是模型的一部分,由一组权重值构成,并且这些权重值在训练过程中会被更新。卷积核与输入数据进行逐元素相乘并求和的操作被称为卷积运算,通过对输入数据应用多个不同的卷积核可以提取不同特征,如边缘检测、纹理识别等。
卷积核的大小和形状可以根据应用需求进行调整,通常选择 3×3、5×5 或 7×7 这样的小型方形矩阵。此外,在深度学习中经常使用多个具有不同尺寸和形状的卷积核,以提高网络对于输入数据差异化信息的学习能力,从而进一步提高分类和预测的精度。
因此,卷积核在卷积神经网络中起到了既关键又基础的作用,其正确性和优化都对网络性能有着重要的影响。
特征图
在卷积神经网络中,特征图(Feature Map)指的是经过一系列卷积操作和激活函数等处理后得到的输出矩阵。每个卷积核都可以看作一个模板,在输入数据上进行滑动并计算与之对应的权重值列表,最终得到一个新的输出矩阵就是特征图。
特征图通常具有高维度和多通道的特点,其中每个像素点代表了一组输入数据经过卷积变换和激活处理后的某种抽象表示。这意味着,特征图在空间上也保留了原始数据的局部相关性,并且已经被赋予了更高层次、更抽象的语义信息。在深度学习中,这些特征图将成为构建整个网络的基础,用于数据分类、对象检测、图像分割等任务。
需要注意的是,不同的卷积层会学习到不同类型的特征,初级卷积层更依赖于边缘、形状等低层次特征,而高级卷积层则依赖于更复杂的语义特征,如纹理、结构、目标等。因此,通过将输入数据沿着卷积神经网络的层次进行处理,可以不断提取更抽象、更具有区分性的特征信息,从而使网络对输入数据的理解和处理更加准确、高效。
感觉就是为了抽象、分类?
池化
池化(Pooling)是卷积神经网络中一种常见的操作,它通过采样输入特征图中小区域内的最大值或平均值来降低网络计算量,同时减少了数据维度,也不会引入额外的参数。通常情况下,池化操作紧接着卷积操作进行,可以有效缩小特征图的大小及特征空间,并使模型对位置偏移、细微形变等不敏感而具有更强的鲁棒性。
最大池化(Max Pooling)和平均池化(Average Pooling)是两种常见的池化操作。最大池化将输入分为一个个的小矩阵,在每个小矩阵中找到最大值作为输出;平均池化则取小矩阵内所有数的平均数。这些小矩阵也称为池化窗口,其大小和步幅可根据应用需求进行调整。
在计算机视觉任务中,池化能够在保留重要的特征信息的前提下,过滤掉一些冗余的信息,加快网络收敛速度和训练效果。但是,过多的池化操作可能会导致信息丢失,因此需要在模型设计中谨慎处理池化与卷积操作的次数和顺序。近年来,一些新型神经网络,比如 ResNet 或 DenseNet 等使用跳跃连接(Skip Connection)、特征融合等技术去减轻池化带来的影响,并取得了优异的性能。
过拟合
过拟合(Overfitting)是指机器学习模型在训练时过度地学习了训练数据的特征,导致在未知数据上的预测性能下降。即,过拟合的模型在训练数据上表现得很好,但在测试数据上表现不佳。
过拟合通常是由于模型太复杂或训练数据太少导致的。当机器学习模型在训练过程中拟合了噪声或训练数据中的随机性,或者训练样本的数量太少时,就容易发生过拟合。在这种情况下,模型会把噪声或随机性当做真实数据特征,导致在测试数据上的预测性能下降。
为了避免过拟合,可以采用以下方法:
增加训练数据量,尽可能让数据能够覆盖到不同情况下的使用场景。
对训练数据进行预处理,如数据归一化、特征选择、降维等,以减小噪声和随机性的影响。
添加正则化项,如 L1 正则化和 L2 正则化,以限制模型参数的大小,并减小过拟合的风险。
采用早期停止法,在模型训练过程中,发现模型在验证数据集上的准确率开始下降时就停止训练,以避免模型过度拟合训练数据。
使用集成学习方法,如随机森林、神经网络中的 Dropout 等,以减小模型的方差,增加模型的泛化能力。
需要注意的是,过拟合是机器学习模型面临的一个普遍问题,需要开发人员在模型设计和训练中注意防止。
泛化
泛化(Generalization)是机器学习中的一个重要概念,指的是训练后模型在未曾见过的数据上的表现能力。简单来说,泛化能力就是使用已经学习到的知识和经验解决新问题的能力。
机器学习模型的目标是通过训练数据中的规律学习到一个预测函数,使得它能够对新的未知数据进行准确的预测。而泛化能力就是衡量一个模型在新数据上的表现能力,是评估机器学习模型质量的一个重要指标。
对于一个机器学习模型来说,好的泛化能力应该具有以下特点:
对于未遇见的新数据,能够保持较好的预测准确性。
对于训练数据的噪声和随机性能够有较好的鲁棒性,不会对预测结果产生过大的影响。
在不同的数据集上表现稳定,不受数据集变化的影响。
提高模型的泛化能力是机器学习中的一个重要研究方向和挑战。常用的方法包括增加训练数据量、使用特定的模型结构、采用集成学习等。在机器学习模型设计和开发过程中,需要不断寻求提高模型泛化能力的方法,并测试模型在测试集上的表现,评估模型的准确度和稳定性。
机器学习和深度学习的区别
深度学习是机器学习的一个子集,机器学习是人工智能的一个子集。
机器学习和深度学习都是人工智能(AI)的分支领域,它们有一些共通的概念和技术,但也有一些显著的区别。下面是它们的一些主要区别:
1.方法:机器学习是一种比较传统的方法,主要使用统计学习方法、常规算法和数据挖掘等技术,进行分类、回归、聚类和降维等任务;而深度学习是一种基于神经网络的方法,通过多层组合非线性变换来提取特征和处理高级别抽象概念,实现自动化的特征提取和模式识别。
2.难易程度:机器学习需要手动提取特征,需要对数据进行人工筛选和选择特征,并且需要针对不同任务进行不同算法的选择和调整,比较依赖于领域知识和经验;而深度学习通常不需要人手动提取特征,可以直接从原始数据中学习到高级别抽象特征,实现端到端的学习过程,但也相对需要更多的计算资源和数据量。
这就是为什么韩博一直强调,分类是 GPT 给的,不是我们自己设定的。这是深度学习的思维模式。
3.适用范围:机器学习比较适合在小样本和有限数据情况下进行模型训练和预测,例如非结构化数据的处理、传感器和文本数据等;而深度学习更多适用于大数据、复杂数据和高度抽象特征的问题领域,例如计算机视觉、自然语言处理、语音识别等。
4.库和工具:机器学习的常用开源库有 scikit-learn、XGBoost、LightGBM 等;而深度学习的常用开源库和框架有 TensorFlow、PyTorch、Caffe 等。
虽然机器学习和深度学习有不同的方法、难易程度、适用范围等区别,但它们都是 AI 的重要方向,相互补充、互相借鉴,在不同的场景下提供了丰富的解决方案。
迁移学习
泛化和迁移学习(Transfer Learning)是机器学习中两个不同的概念,它们在解决问题时采取了不同的方法。
泛化泛指模型对未知数据的预测能力,即模型在训练数据上学习到的模式能否泛化到新的数据上。当模型具有良好的泛化能力时,无论是在训练集内还是在未知的测试集上,模型的表现都能够达到很好的水平。
迁移学习则是指将已经学习好的模型的部分参数或整个模型应用到新的任务上,以提高新任务的表现。迁移学习是从已经训练好的模型中提取知识,将其用于解决新问题的一种方法。这样可以在新任务上从更高的起点开始,加快学习的速度并提高性能。
简单来说,泛化是指模型在训练数据和测试数据上的表现能力,它考量的是模型表现的不确定性和稳定性;而迁移学习则是指用预先训练好的模型或其学习到的特征来加速新的学习任务,并提高其表现。
需要注意的是,泛化和迁移学习并不是互斥的概念,它们可以相互结合使用,例如,使用有良好泛化能力的模型来进行预训练,然后将预训练好的模型应用于新的迁移学习任务中。
收敛
收敛是指一个计算过程或者迭代算法在不断迭代之后逐渐趋近于一个稳定值的状态。通俗来说,就是当不断迭代的过程中逐渐逼近某个稳定的解,且不再发生明显的变化。对于优化问题和机器学习中的模型训练而言,收敛意味着算法已经找到了一个可以接受的解,且不再有大的变化。在训练深度神经网络的过程中,通常的目标是通过不断调整神经网络的权重和偏置,让训练误差(或者验证误差)不断减小直到收敛,得到一个最优的模型。当模型训练时达到收敛状态,就表示算法已经找到了最优解或者最优解的近似。
多模态
多模态(Multimodal)是指在人机交互中以多种方式进行交流和传递信息的方式。它包含了多种形式的交互元素,如语音、手势、眼神、表情等,从而提供更加丰富、自然和人性化的交互体验。
通过多模态交互,用户可以根据自身的习惯和需要,选择最适合自己的交互方式来与系统进行互动,从而提高交互效率和可用性。例如,在智能手机中,用户既可以使用语音命令,也可以使用手势或触摸屏幕进行操作,这些方式相互协作,为用户提供了更加便捷和舒适的体验。
多模态交互已广泛应用于人机交互、机器人控制、自然语言处理、计算机视觉等领域。在这些领域中,多模态交互可以有效地提高系统对用户的理解和响应能力,从而实现更加智能化、自然化的交互。
涌现
在机器学习中,涌现通常指不同的单元(神经元、决策树节点、随机森林子分类器等)之间的相互作用所产生的出人意料的行为。这些行为可能来自于模型本身的结构和参数,也可能源于所使用的数据集的某些特性,并且很难被预测。
机器学习中的涌现表现在许多方面,例如:当我们训练一个模型时,模型可能会产生出人意料的结果、泛化能力超出我们的预期、对欠拟合或过拟合的数据表现具有鲁棒性、模型可以通过自我组合产生新功能等。这些现象可能导致模型产生更高的准确率、更好的泛化能力、更适应多变数据的变异因素,甚至是超越人类准确率的效果。
涌现在机器学习中被视为一种有利的现象,因为它迫使我们扩大对模型的理解和探索,深入了解数据集的内在特征,并评估不同的算法和架构结构的相互作用。 这些知识可用于增加我们的信心来部署我们的模型到真实世界中,并提高我们的“黑盒”模型解释力,更好地理解我们的模型如何做出决策。
剪枝
剪枝是指在决策树、搜索树等数据结构中,对某些不必要的分支或节点进行裁剪,以达到降低计算复杂度、提高算法效率或减少噪声干扰等目的的过程。剪枝可以基于不同的原则和方法,如最小误差剪枝、代价复杂度剪枝、悲观剪枝、预剪枝、后剪枝等。在机器学习、人工智能、计算机视觉等领域中,剪枝是非常常见和重要的技术手段之一。
量化
在机器学习中,量化(Quantization)是将浮点数权重和偏置等参数转换为较小的整数或极限小数的过程。
这个过程主要是出于优化模型存储和计算效率的考虑。在深度神经网络中,每个参数与其相关的梯度需要存储在内存和磁盘上,占用了较多的存储空间并且导致较长的训练和推理时间。通过量化这些参数,我们可以有效地减少对存储资源的需求和数据传输带宽,并提高计算速度与效率。
通常来说,参数量化主要有以下几种方式:
静态量化:先分析一批数据,然后基于它们的范围来选择动态范围,或者使用某种标准差或其他统计特征来进行量化。
动态量化:根据实时数据来调整参数值,以适应变化的数据分布。通常需要更多监控和预测技术,以便跟踪变化。
分块量化:将待处理的大数据分成多个部分进行量化处理,以适应不同部分的数值特性,并减少模型压缩畸变的发生。
尽管量化参数会对模型精度带来一定的影响,但有研究表明,合理的量化方法可以在保持模型精度的同时将存储需求降低 4 倍以上、延迟降低 30%,大幅提高网络效率和减少运行成本。因此,量化技术已经被广泛地应用于部署深度学习模型和 IoT 设备上,以获得更好的计算资源利用率和系统性能。
在机器学习中,量化到 2bit、4bit等是指通过将模型参数的值限制在极少的几个位数(比如 2 或 4 个比特),来进一步压缩和优化深度神经网络的存储需求和运算成本。这种方法也被称为低精度量化。
通常情况下,机器学习领域中常用的模型的权重和偏置参数都是由32 位浮点数或更高位数的数字表示。采用低精度量化技术,可以尽可能地缩小参数矩阵中每个数的位数,以降低资源消耗和计算时间,并提高硬件设备的效率。例如,将权重参数从 32 位浮点数量化为 2 位或 4 位,则可以减小参数存储大小,节约内存占用和数据传输带宽,并且加速推理过程。
具体地,采用低精度量化技术进行神经网络模型的训练和优化,需要对量化后的参数进行重新校准,保证其能够正确描述模型的结构和特征。此外,还要结合实际的应用场景和问题,选择最适合目标的不同量化级别和方法,例如分块量化和动态量化等。
虽然低精度量化有助于提升深度学习模型的效率和推理速度,但必须平衡精度损失和计算资源利用的权衡关系。多种研究都已指出低精度量化会降低模型的精度,并且极端低位数的量化通常产生更明显的精度下降,因此在具体应用中仍需选择适当的精度水平以及精度和运行时间之间的权衡。
Token
Token,又被称为标记(Tokenization),指的是将文本划分成一系列单独的单元,例如单词、短语、符号等等。在自然语言处理(NLP)中,Token 通常用于在文本中识别和提取单个单词或短语,以便于对文本进行处理和分析。
Token 生成通常涉及到以下几个步骤:
- 预处理:在生成 Token 之前,需要对文本进行预处理,例如删除标点符号、转换为小写字母等处理操作。
- 划分:通过空格、标点符号及其他分隔符号对文本进行划分,从而得到一系列的 Token。
- 清理:删除无关的 Token,例如数字、标点符号等。
- 标记化:将每个 Token 转换为其规范形式,例如将单词转换为它们的基本形式或词根。
在 NLP 中,Token 生成是一个非常基础性的技术,许多 NLP 任务都需要它,例如文本分类、命名实体识别、机器翻译等。它可以帮助我们更好地理解文本的含义和结构,从而更好地完成各种 NLP 任务。
Embedding
标签,是词元(Token)经过转换后形成的一个包含 768 个数值的向量。
PyTorch
PyTorch 是一个由 Facebook 人工智能研究团队开发的开源机器学习框架,是一个基于 Python 的科学计算包,被广泛地应用于自然语言处理、计算机视觉、语音识别等领域的深度学习任务。PyTorch 的底层运算是基于 Torch 实现的,它的特点是动态计算图(Dynamic Computational Graph),因此更加灵活和易于调试。
PyTorch 支持动态、静态的计算图,包括反向自动求导,可以准确地记录每个节点的求导历史。这个特性使得模型的定义和修改变得更加容易和自由,也使得模型的调试更加容易。
PyTorch 由 Facebook AI Research 团队开发并维护。 PyTorch 的主要特点是动态计算图,这使得用户可以在运行时动态地定义计算图,极大地提高了模型的开发和调试效率。它还支持强大的 GPU 加速计算,使得模型能够高效地运行。PyTorch 也提供了许多高级的功能,如自动微分、适应性优化器和分布式训练等,它们可以帮助用户更轻松地构建和训练深度学习模型。
WebGPT
WebGPT 是一种基于 GPT (Generative Pre-trained Transformer)模型的网络文本生成技术,它专门用于在 Web 上生成文本内容。WebGPT 使用了大量的 Web 页面和网站的文本数据进行预训练,从而可以更好地模拟 Web 上的文本风格和用语。WebGPT 可以用于生成各种类型的文本,包括一些任务特定的文本,如电子邮件、推文、产品说明等等。它可以帮助企业、个人等实现更快速、高效的文本内容创作,并在一定程度上减轻了人工撰写文本的负担。
Google Brain 的论文
AGI
AGI(artificial general intelligence,通用人工智能)是一种人工智能系统,指的是在广泛的认知任务方面都能够表现出与人相似的智能水平的人工智能。AGI 代表着 “通用人工智能” 或 “超级人工智能”,是与 “弱人工智能” 相对的概念(指其只在特定任务领域呈现出高级的表现形式,而在其他领域表现平凡)。
AGI 的目标是构建一个能够像人类一样进行智能思考,具有自我意识、理解和学习能力等全面性特征的人工智能系统。与传统的人工智能不同,AGI 具有更广泛、更高层次的智能特点,能够更加适应人类的需求,具有更重要的现实意义。当前,AGI 仍在研究阶段,尚未实现。
RLHF
RLHF(基于分层结构的强化学习)是强化学习中基于分层结构的方法,全称为 Reinforcement Learning with Hierarchical Functions。该方法可以将一系列相关的子任务合并成一个更高层次的任务,从而实现更高效的强化学习。
具体来说,RLHF 将任务分为多个层次,每个层次表示不同的抽象程度。高层次表示更广泛的目标,低层次表示具体的操作。每个层次之间都有一组可选操作,这些可选操作本质上是一个函数集,他们通过底层的数据流交互得以联合工作。
在 RLHF 中,每个层次可以利用已经学习到的知识来解决低层次的问题,从而提高效率。通过联合学习所有层次的知识,RLHF 方法能够在更快的时间内收敛,并且具有更高的效率和准确性,适用于具有复杂分层结构的任务。
RLHF 最早是 DeepMind 17 年提出的,即使用在语言模型上,也是 DeepMind 的麻雀先用上的。
InsturctGPT
InstructGPT 是一种基于 GPT 模型的指导性文本生成系统,它可以根据用户输入的任务要求,生成合适的操作指导并生成对应的步骤。这个系统通过对指导性信息进行理解和分析,以生成指导性文本信息,并生成特定领域内步骤的详细说明,例如在厨房烹饪过程中的具体做法、在工地上使用工具的说明、在制药过程中的步骤等等。
InstructGPT 基于预先训练的 GPT 模型,使用了大规模的自然语言文本来预测下一个单词的可能性,并生成相应的文本,但是它与传统 GPT 不同的是,它需要理解用户的任务要求和指导性信息。与传统的文本生成技术相比,InstructGPT 可以提供更加准确、直观的指导性信息,使用户能够更加高效地完成任务。
特征向量
特征向量是指在线性代数中,一个矩阵所对应的线性变换的特征值方程中,每一个特征值所对应的特征向量。换句话说,特征向量是一个矩阵相对于某个特定方向的向量变化情况,它在矩阵运算中具有重要作用。
在具体计算中,矩阵可以看作是一个线性变换,每个矩阵都有一些特殊的变换方向,这些特殊的方向就是特征向量。一个 n 维实数向量空间中的特征向量和特征值通常用于对向量空间的线性变换进行描述。对于一个 n x n 矩阵 A,其特征向量是指一个 n 维非零向量 v,使得它乘以矩阵 A 的结果,等于一个常数 lambda 乘以它本身。即 Av = lambda * v,其中 lambda 为特征值。特征向量衡量了某个变换矩阵在某一定方向上的变化情况,它与特征值是一一对应的,矩阵的特征向量越多,矩阵的特征值越多,这有助于我们更好地理解和分析矩阵运算的性质。
深度学习的可解释性论证
现在 ChatGPT 的底层技术,几乎都是来源于 Google - Transformer,RLHF 等。
TPU
Google 的护城河:Android、TPU
TPU 全称为 Tensor Processing Unit,是一种由 Google 公司开发的专门用于加速机器学习的 ASIC(Application-Specific Integrated Circuit)芯片。TPU 最初是为 Google 自身的机器学习和深度学习工作负载而设计和优化的,对于现代机器学习的计算密集型工作,TPU 可以提供从数十到数百倍的加速,大大缩短了训练模型所需的时间。
TPU 芯片的设计注重于高速运算和内存可扩展性,在设计过程中充分考虑了机器学习算法的特定需求。比如,在深度神经网络的训练过程中,TPU 可以轻松处理大量的矩阵计算,从而大大提高训练速度。与传统的 GPU 相比,TPU 在处理规模较大的机器学习工作负载时具有更好的性能和效率。
总的来说,TPU 是一种专门为机器学习和深度学习工作负载而设计的硬件加速器,可以大幅度提高模型训练的效率和速度。
DeepMind
DeepMind 是一家伦敦人工智能科技公司,成立于 2010 年,旨在推动人工智能领域的发展和创新,并将其应用于实际问题中。它的创始人包括伊隆·马斯克(Elon Musk)、彼得·西克耶克(Peter Thiel)和 Demis Hassabis 等人,后来被谷歌收购。
DeepMind 的主要研究方向包括机器学习、深度学习、神经科学等领域,该公司的成果在人工智能领域引起了广泛关注。它在 AlphaGo、AlphaZero、AlphaFold 等领域都实现了重大突破,尤其是在围棋、下棋游戏等领域取得了全球领先的成就,目前 AlphaGo 已被公认为世界上最优秀的围棋选手之一,这是具有里程碑意义的技术突破。
DeepMind 的愿景是建立通用人工智能(AGI),它将人工智能作为一种智能工具,帮助解决世界上一些复杂、具有挑战性的问题。
chatgpt3、chartgpt3.5、chatgpt4 的区别是什么?
第一性原理
第一性原理是指把一个问题或系统的行为、特性和性质,基于最基本原则和基本规律来分析和描述的方法。这些原则和规律来自于物理、化学、数学等领域内的基本定律和公理,是一种基于严密逻辑推理和实验验证的科学方法。在科学研究中,第一性原理方法被广泛应用于材料科学、化学、物理学等领域的计算科学、理论模拟和理论设计中。
模型蒸馏
模型蒸馏技术(Model Distillation)是一种通过将一个大型模型的知识转移到一个小型模型
模型蒸馏技术是一种用于压缩深度神经网络模型的技术,通过将一个较大的模型(教师模型)的知识传递给一个较小的模型(学生模型),从而实现模型的压缩。在这个过程中,教师模型通常是一个较为复杂的模型,它可以通过更长的训练时间或更多的数据来得到更好的性能。学生模型则是一个较小的模型,它的结构和参数数量都比教师模型少,因此训练速度更快、存储空间更小,但是性能可能会受到一定的影响。模型蒸馏技术的目标就是在保持学生模型尽可能小的同时,尽量保留教师模型的性能。
冻结参数
在深度学习中,经过训练的模型通常会包含很多参数,这些参数可以用来表示模型中各个层之间的连接权重和偏置项等信息。在一些场景下,我们希望在已经训练好的模型基础上,对模型进行一些微调或者使用模型进行预测。此时,为了保证模型的稳定性和可靠性,我们需要冻结模型参数,即在微调或者预测过程中不再更新模型中的参数。
冻结模型参数的方法通常是在训练过程中将某些层或者某些参数设置为不可训练,这样在后续的微调或者预测过程中,这些层或者参数就不会被更新。这样做的好处是可以减少模型在新任务上的过拟合风险,同时也可以加速模型的微调或者预测速度。
P-Tuning v2
P-Tuning v2 是百度推出的一种预训练模型微调技术,是对 P-Tuning 技术的升级版。与传统的微调方式不同,P-Tuning v2 可以在不需要训练大规模数据的情况下,通过对预训练模型中特定参数的微调,来适应特定的任务。这种技术可以在保证模型性能的同时,大大减少了训练时间和计算资源的消耗。
P-Tuning v2 的关键在于对预训练模型中的参数进行微调。具体来说,P-Tuning v2 会根据目标任务的特点,对预训练模型中的一些参数进行微调,使得模型能够更好地适应目标任务。这种微调方式不仅可以提高模型的性能,还可以大大减少微调过程中需要的训练数据量,从而大大提高了模型的训练效率。
P-Tuning v2 技术的应用范围非常广泛,可以用于文本分类、情感分析、问答系统等多种自然语言处理任务。
DeepSpeed
DeepSpeed 是一个Microsoft Research开发的开源库,用于训练非常大的深度学习模型。它提供了一些优化技术,如分布式训练、梯度累积等,可以帮助用户训练更大的模型,同时减少了训练时间和资源消耗。此外,DeepSpeed 还提供了一些自动优化功能,如自动调整学习率、自动调整梯度累积等,可以帮助用户更轻松地训练高质量的模型。
训练数据中的 train、dev、test 分别是什么意思?
在机器学习中,通常会将所有的数据集分为三部分:训练集(train set)、验证集(dev set 或 validation set)和测试集(test set)。其中,训练集用于模型的训练,验证集用于调整模型的超参数以及选择合适的模型,而测试集则用于评估模型的泛化能力。
具体来说,训练集是用来训练模型的数据集,模型会根据训练集中的数据进行学习和调整参数。验证集是在训练过程中用来评估模型性能的数据集,主要用于选择合适的模型和调整模型的超参数。测试集是在模型训练好之后,用来评估模型泛化能力的数据集,模型在测试集上的表现往往是最终评估模型好坏的标准。
需要注意的是,训练集、验证集和测试集的划分需要保证数据集的独立性和随机性,以避免模型过拟合或欠拟合的问题。
模型训练中,训练集(train set)、验证集(dev set 或 validation set)和测试集(test set)全部用同样的数据,会有什么问题没?
如果在模型训练中,使用同样的数据集来训练、验证和测试模型,可能会导致模型过拟合,即模型在训练数据上表现得非常好,但在测试数据上表现很差。这是因为模型已经过度拟合了训练数据,无法泛化到新的数据上。
为了避免过拟合,我们需要将数据集分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调整模型的超参数,测试集用于评估模型的性能。这样可以确保模型在未见过的数据上具有良好的泛化能力。
另外,如果在训练过程中使用测试集来调整模型的超参数,则测试集的性能评估结果可能会过于乐观,因为模型已经在测试集上进行了调整。这样会导致模型在实际应用中的表现不如预期。因此,验证集的使用是非常必要的。
模型训练中,训练集(train set)、验证集(dev set 或 validation set)和测试集(test set)的数据量比例设置为多少比较好?
在模型训练中,训练集、验证集和测试集的数据量比例设置需要根据具体的情况进行调整,没有一个固定的标准。但是,一般来说,常见的比例设置为:
- 训练集:验证集:测试集 = 6:2:2 或 7:2:1
其中,训练集占总数据集的比例应该最大,因为模型的训练需要大量的数据。验证集和测试集的比例可以根据具体情况进行调整,但是它们的比例应该相等,以确保评估模型的性能时具有可比性。
需要注意的是,数据集的大小和比例设置会对模型的性能和泛化能力产生影响。如果数据集过小,模型可能会过度拟合,无法泛化到新的数据上;如果数据集过大,模型训练的时间和计算成本也会增加。因此,在设置数据集比例时,需要根据具体情况进行调整,以达到最佳的模型性能和泛化能力。
机器学习中的 EM、BLEU、CodeBLEU 分别是什么?
EM、BLEU 和 CodeBLEU 都是机器学习中常用的评价指标。
EM 是精确匹配指标,用于衡量模型生成的文本是否与参考答案完全一致。如果完全一致,则 EM 值为 1,否则为 0。
BLEU 是一种基于 n-gram 的指标,用于评估机器翻译的质量。它通过比较机器翻译结果与参考答案之间的 n-gram 重叠度来衡量翻译质量。BLEU 值越高,表示机器翻译质量越好。
CodeBLEU 是一种类似于 BLEU 的指标,但是它是专门用于评估程序生成模型的质量的。与 BLEU 不同的是,CodeBLEU 考虑了词法和语法结构,以及代码的执行结果。CodeBLEU 值越高,表示程序生成模型的质量越好。
需要注意的是,这三种指标都不是完美的评价指标,它们只能提供一些参考。在实际应用中,还需要结合其他指标和人工评估来综合评估模型的质量。
loss
在机器学习中,loss(损失)是指模型预测结果与真实结果之间的差异,也可以理解为模型的错误率。在训练过程中,我们通过最小化 loss 来优化模型,使得模型的预测结果更加接近真实结果。通常,我们使用一些常见的 loss 函数,如均方误差(MSE)、交叉熵(Cross Entropy)等来计算 loss 值。在训练过程中,我们通过反向传播算法来计算模型参数的梯度,并使用优化器来更新参数,以最小化 loss 值。
在机器学习中,loss 的大小并不能简单地用一个固定的数值来衡量。因为不同的问题、不同的数据集以及不同的模型都会导致不同的 loss 值。因此,我们需要根据具体情况来评估 loss 值是否合格。
通常来说,我们会通过观察模型在训练集和验证集上的 loss 值来评估模型的性能。在训练过程中,我们希望模型的 loss 值能够尽量小,但是过于小的 loss 值可能会导致过拟合的问题。因此,我们需要在验证集上观察模型的 loss 值,以确定模型是否具有良好的泛化能力。
在实际应用中,我们还需要考虑到具体问题的需求和约束。例如,在某些需要高精度的任务中,我们可能需要将 loss 值控制在一个较小的范围内。而在某些实时性要求较高的任务中,我们可能更注重模型的速度和响应能力,而不是 loss 值的大小。因此,对于不同的问题,我们需要综合考虑多个因素来评估模型的性能。
s/it
在机器学习训练中,s/it 通常表示”substitute/replace it”,即将某个变量或参数替换为另一个变量或参数。这通常是在训练过程中进行的,目的是改进模型的性能。例如,当我们发现某个参数对模型的性能影响较大时,我们可以使用 s/it 来替换该参数,以期望获得更好的结果。s/it 通常是在代码中使用的一种简写方式,用于快速替换变量或参数。
s/it 前面的数字通常表示替换操作的次数。例如,如果我们使用“s/it 3”来表示替换操作,那么就意味着我们将要进行 3 次替换操作。这种操作通常用于在训练过程中对模型进行优化,以改进其性能。在实际应用中,s/it 操作的次数通常是根据实验结果和经验来确定的,以获得最佳的性能提升效果。因此,s/it 前面的数字表示的是替换操作的次数,而不是任何具体的单位。
应用场景
写文章、画画、编代码,都已经有成功例子。从中可以看出,AI 一定要集成到人工创作的场景里,才最好用。在这样的场景,才能行云流水地给 AI 提需求,和修正、发布 AI 给出的建议。比如我,已经决定对集成到 VS Code 里的 copilot 付费了,但用 ChatGPT 辅助写代码就太绕了。
按照这个模式推论,所有创作场景,都值得尝试下 AI 辅助。比如低代码开发,运营活动页搭建,短视频剪辑,BI 图表制作等有经验的人已经干腻了,没经验的人又干不好的场景。
AI 肯定比没经验的人干得好,且因为替有经验的人完成了大量乏味工作,而获得认可。
插件
精-很不错的插件调研:
https://zhuanlan.zhihu.com/p/629337429
感觉业务编码都会用自然语言 Prompt 搞定!今后的模式可能是:
Service API 提供基础能力服务+自然语言编写业务逻辑
简单实现一个 ChatGPT Plugin:
https://zhuanlan.zhihu.com/p/629207240
UI/UE 设计
还有一个有望获得新机会的岗位,是 UI/UE 设计师。
系统间的 NLI 还很远,但 UI 的 NLI 化,已箭在弦上。
还记得罗永浩的坚果 TNT 工作站吗?虽然那时是笑话,但现在已是机会。
键盘鼠标之外,又增加了自然语言控制。传统 UI 的操作范式肯定会发生改变。
我判断,UI 设计的要点会越来越强调反馈,而不是键鼠操作。可能要留一定的微调能力,但像向导、创建、删除、批处理等,都会变成直接响应自然语言。「What you see is what you say」会成为核心设计语言。
文本
图片
视频
3D 模型
软件开发
软件工程师也要做出调整。所有的软件设计可能都要 Agent-Oriented,这意味着模块化是强制必须的,然后交给 AI 去做满足用户需求的模块组合。
模块内部要多 AI,得看需求和粒度。当 AI 对算力的要求降到某个阈值时,可能简单的模块功能,也可以考虑用 AI 实现了。
如果说 AGI 的出现,率先让程序员的数量减少了,我一点儿也不奇怪。毕竟《产研的宿命就是让自己越来越不重要,直到被裁掉》
程序
AIGC 生成个性化游戏场景/副本。
话题
AI 会导致大量失业么?
人的劳动价值越来越低,情感价值就越来越大。
AI 世界里,少数人类,在不断完善 AI,多数人类依靠情感活着,用情感创造价值。
行业资讯
路奇:理解新范式,拥抱新时代(是上一篇的完整版,含演讲稿内容,密码:HRtD):
https://miracleplus.feishu.cn/docx/CS8ydhVISokvnaxUAQ5c2OvynbP
新一代的系统:从搬运信息到理解信息,从副驾驶员到教授。
陆奇最新演讲时表示 OpenAI 发展边界未来比谷歌大,可能大 10 倍,判断依据有哪些?你怎么看?
https://www.zhihu.com/question/597428103/answer/2999427066
AutoGPT 介绍:
https://mp.weixin.qq.com/s/rS5i3prVKqFDA62qpj3UPg
Auto-GPT:
https://github.com/Significant-Gravitas/Auto-GPT
大模型训练避坑指南_javastart 的博客-CSDN 博客
Prompt
让 Chatgpt 回答强大十倍——prompt 技巧宝典:
https://zhuanlan.zhihu.com/p/617893506
awesome-chatgpt-prompts:
Prompt 指令大全:
提示技术:
https://www.promptingguide.ai/zh/techniques
应用&玩法
ChatGPT 都有些什么好玩的玩法?
https://www.zhihu.com/question/571619870/answer/2922993093
(TODO)模型的数据结构是什么?
搞清楚模型的数据结构,就能理解清楚了
如何提升 LLM 在某个特定任务上的能力?
单独提升 LLM 在数据可视化设计上的能力
要提升 LLM 在某个特定任务上的能力,比如数据可视化设计,可以采取以下几个方法:
微调 (Fine-tuning): 首先,将语言模型预训练模型的参数加载到新的任务中,并在新任务的数据集上进行微调以适应特定任务的数据分布和特点。此过程有助于改进模型的性能,提高模型在特定任务上的准确性。
数据增强: 为了在数据可视化设计方面进行训练,我们可以使用各种技术增强数据集,例如通过对训练数据进行变形。这有助于向 LLM 模型展示更多的情景,以使模型更好地理解和处理数据可视化相关的任务。
任务特定提示 (Task-specific Prompt): 设计适当的任务特定提示对于提高 LLM 在某个特定任务上的性能是至关重要的。在设计提示时,建议采用专家知识或先验信息,以便指导模型正确地学习有关数据可视化设计的特定知识和技能。
结合其他技术:可以使用其他相关技术来提高 LLM 模型在特定任务上的性能,例如基于规则的方法、增量学习等。
综述而言,如果要提高 LLM 在某个特定任务上的能力,需要采用微调技术、数据增强、任务特定提示和结合其他技术的方法进行训练。这些方法将有助于 LLM 模型学习数据可视化设计相关的知识和技巧,以提高模型在这个任务上的性能。
常用模型微调技术
常用的模型微调技术包括以下几种:
Fine-tuning(微调):Fine-tuning 是最常见的模型微调技术,它通常是在一个预训练模型的基础上,使用新的数据集进行微调。Fine-tuning 的优点是可以快速地适应新的任务,缺点是需要大量的标注数据。
Transfer learning(迁移学习):Transfer learning 是一种将已经训练好的模型应用于新任务的方法。它的优点是可以利用已有的知识来加速新任务的学习,缺点是需要选择合适的预训练模型以及进行适当的微调。
Multi-task learning(多任务学习):Multi-task learning 是一种同时训练多个相关任务的方法。它的优点是可以共享模型的参数,从而减少训练时间和计算资源的消耗,缺点是需要处理好任务之间的关系,以及在任务之间平衡模型的性能。
Knowledge distillation(知识蒸馏):Knowledge distillation 是一种将一个大型的模型的知识压缩到一个小型的模型中的方法。它的优点是可以在保证模型性能的同时,大大减少模型的大小和计算资源的消耗,缺点是需要选择合适的压缩方法以及权衡模型大小和性能之间的关系。
不同的微调技术适用于不同的任务和场景,需要根据具体的情况选择合适的方法。其中,Fine-tuning 是最常用的方法,因为它简单易用,适用于大多数任务。但是,对于数据量较少的任务,可以考虑使用 Transfer learning 或者 Knowledge distillation 等方法来提高模型的性能和训练效率。
Fine-tuning、LoRA、P-Tuning v2 有何关系?有何区别?
Fine-tuning、LoRA 和 P-Tuning v2 都是针对自然语言处理任务的预训练模型优化技术,它们的共同点是都利用了预训练模型的特征来优化目标任务的性能。但它们之间也有一些区别。
Fine-tuning 是一种常见的预训练模型优化技术,它的基本思想是在预训练模型的基础上,针对目标任务进行微调。具体来说,我们可以首先使用一个大规模的语料库来预训练一个模型,然后将这个模型的参数作为初始参数,再使用目标任务的数据对这个模型进行微调,以提高模型在目标任务上的性能。
LoRA(Language-Optimized Representation for Attention)是一种基于注意力机制的预训练技术,它的主要思想是通过在预训练模型中引入一些语言优化的机制,来提高模型在自然语言处理任务上的性能。具体来说,LoRA 在预训练模型中引入了一些额外的任务,例如语言模型、掩码语言模型和句子级别的任务等,以帮助模型更好地学习语言的结构和语义信息。
P-Tuning v2 是一种基于知识蒸馏的预训练技术,它的主要思想是将一个大型的预训练模型的知识蒸馏到一个小型的模型中,以提高小型模型在目标任务上的性能。具体来说,P-Tuning v2 首先使用一个大型的预训练模型来生成一组伪标签,然后将这些伪标签与目标任务的真实标签一起用于训练一个小型的模型,以提高模型在目标任务上的性能。
总的来说,Fine-tuning、LoRA 和 P-Tuning v2 都是预训练模型优化技术,它们都可以用于提高模型在自然语言处理任务上的性能。但它们的具体实现方式、优化目标和应用场景等方面存在一些差异。
如何确保结果的正确性?
https://mp.weixin.qq.com/s/6e7T7Px3vufxMcT0_GgX-g
随着 LLM 的发展,涌现了关于 prompting 的一些工作,其中有两个主流方向:
一个以 Chain-Of-Thought( CoT,思维链) 为代表,通过清楚得写下推理过程,激发模型的推理能力;
另一个以 Self-Consistency (SC) 为代表,通过采样多个答案,然后进行投票得到最终答案。
PHP 尝试模拟更加类人推理过程:对上次的推理过程进行处理,然后合并到初始的问题当中,询问 LLM 进行再次推理。当最近两次推理答案一致时,得到的答案是准确的,将返回最终答案。具体的流程图如下所示:
工具
Mubert 音乐生成:
图像生成
相关技术:stable diffusion prompts
要付费的
Dream Studio:
https://dreamstudio.com/create/
NightCafe:
这个也要收费
Wombo Dream:
Best 100+ Stable Diffusion Prompts: The Most Beautiful AI Text-to-Image Prompts:
https://mpost.io/best-100-stable-diffusion-prompts-the-most-beautiful-ai-text-to-image-prompts/
开源工具-imaginAIry:
https://www.yuque.com/fangkuaier-klqlh/mgdkrq/oy6cvq9ktk55rcks
https://github.com/brycedrennan/imaginAIry
(TODO)ChatGPT+Unity
https://www.bilibili.com/video/BV1FY411v7vK/
加上换模型、换装、换性格等等,这不妥妥的一个 AI 助理么?
可以考虑用 UE 做,视觉效果可能更好一些。
或者先用 Three.js + 那个动画网站,搭配 GPT 搞一下,就可以出来了。
资料
(精)AIGC 介绍:
https://mp.weixin.qq.com/s/t0Ml7E-CvlKfdaUMBGKJBg
(TODO)Stable Diffusion 搭建全过程记录,生成自己的专属艺术照:
https://blog.csdn.net/submarineas/article/details/126634227
官方体验地址:
https://huggingface.co/spaces/stabilityai/stable-diffusion
AI 工具汇总:
AIGC 工具介绍:
https://www.bilibili.com/video/BV1DY4y1Z7NR/
YouTube 上有个博主“Mu Li”,视频讲解一些 Open AI 的论文:
《OpenAI codex 论文精读》
ChatGPT 的使用方式(可以当成一位知识渊博的老师):
https://www.zhihu.com/question/570596331/answer/2861569894
(精)当 ChatGPT 遇上 Unreal Engine 数字人:
基于 ChatGPT 的 Github Code Review 机器人:
https://github.com/ruanyf/weekly/issues/2912
(精)viz-gpt 可视化图表生成:
GitHub - ObservedObserver/viz-gpt: Create and edit data visualization with simple chat.
(精)简单实现一个 ChatGPT Plugin: