Three.js-性能优化
最近做了一个集群目标策略的3D可视化项目,前面花了2周时间出了个Demo来进行演示,性能极差,在我的i7-12700H+RTX2050的笔记本上,也会出现卡顿。后面这个还要迁移到移动端,性能问题就更严重了,因此借助解决这个需求的性能问题,把Three.js的性能优化方面的内容整理下,方便今后参考。
CPU or GPU?
可以通过将场景中所有材质改为普通材质,来确定你的网页是依赖CPU的还是GPU的:
1 | |
如果性能有提升,那么说明是依赖GPU的;如果性能没提升,那么就是依赖CPU的。
比如我们做的这个3D目标策略,修改后PC端帧数从80提升到了120,移动端帧数从27提升到了52,那么说明就是依赖GPU的。
内存
模型加载到内存中,占用的内存和显存比硬盘上的模型尺寸往往要大一些。
而像iOS这种,是有单网页内存上限限制的,超过一定数值就会页面崩溃。
Web Worker
web worker 是运行在后台的 JavaScript,它独立于其他脚本,不会影响页面的性能
Physijs物理库就是使用这种方式来保证页面的性能。
我们可以将一些计算类的内容都放到web worker中处理。
控制帧数
默认60帧在某些场景其实用不着,我们人为降低下帧数,也可以提升性能。
不要在render中执行太多操作
UnrealBloom的性能损耗
不要设置冗余的Vue的data属性
Dev-tools分析
渲染阶段
这个不知道是不是和面数有关系,还不知道怎么优化。
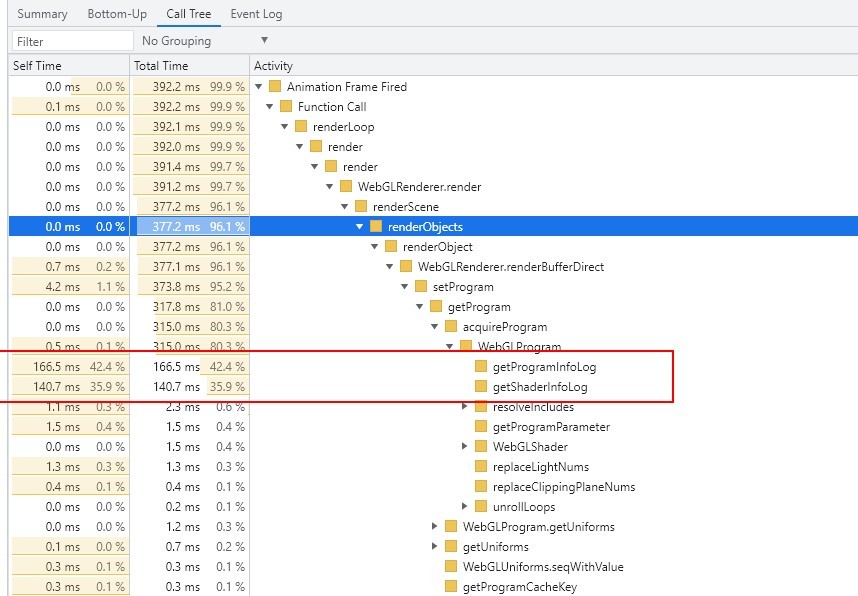
交互阶段
看起来主要是事件的问题。
程序中给renderer设置了intersectRecursive=true,可能有影响。
我设置了这个:
1 | |
操作的时候基本就20-30FPS。
如果去掉这个,那么基本上稳定60FPS。
1 | |
Renderer中的:pointer=”{ intersectRecursive: true}” 是结合Mesh上的@click来生效的。
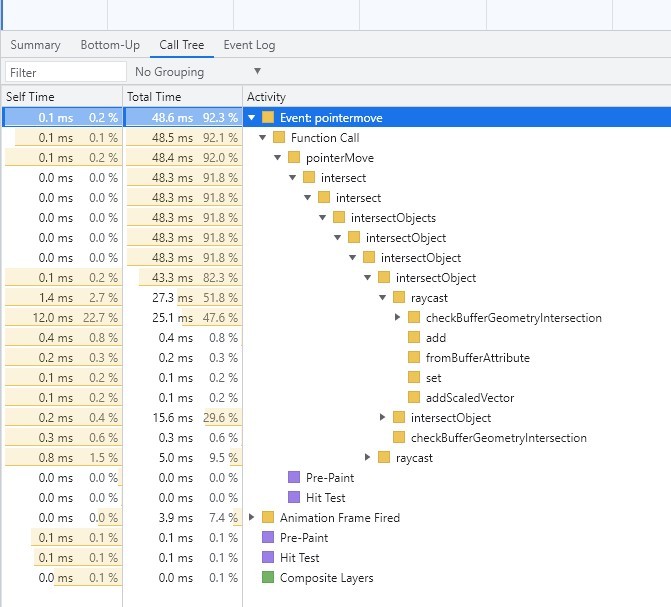
Raycaster.intersectObjects(objects, true)导致的性能问题
Raycaster.intersectObjects()的第二个参数,标注了是否递归检测被命中的元素及其子元素。
如果是一些独立、数量较少的模型场景,这个参数设置为true是没问题的,可以简化操作;但是如果是加载一些层级结构复杂的模型,则这个计算会很耗费性能,因为这是在每一个渲染循环中都会执行的操作。
解决方案:
模型load成功后,我们对需要执行事件交互的模型做一个引用缓存,然后每次执行Raycaster.intersectObjects()的时候,手动将这些模型作为第一个参数传入进去。
onEvent.js也是按照这个思路做的,当用户给某个Mesh注册事件监听的时候,将其加入缓存列表。这样就按需计算了。
注意:intersectObjects()似乎只会针对Mesh生效?一定会拆散模型?
onEvent.js的做法
1、触发事件
2、将Group逐个拆分,放入容器
3、将容器作为参数传入intersectObjects(),确定被点中的Mesh对象是哪个
4、反向通过被点中的Mesh对象,找到绑定事件的根对象
5、触发跟对象的事件函数
onEvent.js有对点击空白区域做拦截,因此我们完全可以舍弃掉再叠加一层Canvas来监听空白点击事件的方式了。
面数多导致RayCaster计算量巨大的问题
比如我们的3D目标策略图、3D汽车产业链,因为模型面数较多,加上射线检测后,转动一下就很卡(给mousemove事件添加了RayCaster的调用)。
解决方案:
1、压缩模型,降低面数
2、防抖节流
3、仅当用户操作停止时,才触发RayCaster
以汽车模型为例,压缩前大约70MB,压缩后7.18MB,但是发现性能还是一样差,似乎压缩模型对于网格没啥效果。
李少杰:
我目前的方案是,先从sence中筛选可见的,不为组的mesh实体,然后挨个判断
假设有N个模型,对应N个射线,每条射线都需要检测N个模型,才能算出有对应的模型有没有被遮挡,全车的时候N很大,大概160多,再加上模型平均面数比较多,大概3-5s才能出结果
改为GPU拾取方案
想着很简单,然后发现还是有不少要注意的点的,比如要剔除光照等因素的影响、性能优化等。
这个的原理,是用单独的一个scene,并指定相机大小,来检测相机中的像素颜色。
几个关键的API:
camera.setViewOffset()
.setViewOffset ( fullWidth : Float, fullHeight : Float, x : Float, y : Float, width : Float, height : Float ) : undefined
fullWidth — full width of multiview setup
fullHeight — full height of multiview setup
x — horizontal offset of subcamera
y — vertical offset of subcamera
width — width of subcamera
height — height of subcamera
WebGLRender.readRenderTargetPixels()
全屏读取的话,这个会不会有性能问题?哪怕读取没问题,遍历判断也会有问题吧?比如我4K显示器:
3840*2160 = 8,294,400,接近830W次判断,我的天~
关键这个还是每一帧都要判断的。
(误,此路不通)额外收获
这个还可以解决在用户无交互的情况下,判断哪些物体被全部/局部遮挡了,比如用于标记操作引导点:
javascript - Three.js detect when object is partially and fully occluded - Stack Overflow
经测试,这个方案不行,因为计算量太大了。
有性能问题,刚想了下,GPU拾取也不适合这个场景,主要问题还是在于这个是无用户操作接入,要针对全场判断
如果是用户鼠标交互,只需要判断一个像素;但是这种全场判断,比如4k全屏,单次判断就要判断830W次;即使做部分裁剪,也在几百万的级别,性能吃不消。
我自己基于官方的这个Demo修改了下,卡成狗了,根本没法用。
其实也有其他一些trick的方法,不是很完美,但会比老方案好一些,比如还是用老方案,但是采样取点多取几个
方案1:WebGL2.0的Query
three.js webgl - Occlusion Queries
https://github.com/mrdoob/three.js/pull/15450
还没合并到Three.js中,要想用,得自己去他的页面源码里面迁移过来才行。
使用WebGL2:
1 | |
Trois默认使用WebGL1.0,问题不大,可以魔改。
但是!WebGL2有个坑:Safari不支持……这样后面移动端没法用。
通过beginQuery制定查询类型,比如遮挡查询:
1 | |
Babylon.js在 3.1版本就支持遮挡查询了。
另外要考虑一个:阴影问题,不显示了就没影子了。
方案2:react-three-drei的occlude
https://codesandbox.io/s/html-markers-6oei7?file=/src/App.js:1943-1950
https://github.com/pmndrs/drei#html
这个我看了下,还是不行
这个也还是通过raycaster进行检测的:拾取物体和相机的距离 VS. 目标物体和相机的距离,通过这个来判断是否被遮挡
我们这个场景,还是会有性能问题
(TODO)方案3:GPU拾取&增加采样点
比如取每个模型的包围盒的8个点+中心点,或者模型球面上的N个点+中心点。
然后仍然用GPU拾取的方案,这样我们如果有300个模型,每个模型取9个点,那么也就只需要计算2700个点,似乎可行?
但是取像素是2D平面的操作,还得先把模型的这些点的3D坐标转为2D坐标才行。最终性能怎么样还不好说。
步骤:
1、单独创建一个PickingScene
2、clone每个独立模型,设置顶点颜色,构建为一个整的Mesh,加入PickingScene:
1 | |
3、帧渲染之前,同步位置信息(可优化,封装为一个函数,打开车门的时候调用下即可)
1 | |
4、离屏渲染PickingScene
1 | |
5、获取每个模型的中心点,转为2D坐标,获取该点的颜色,判断是否被遮挡
6、给未被遮挡的对象,进行业务处理
程序设计方面:
1、封装为一个Helper
1 | |
遇到的坑
Material设置了vertexColors: true之后,不能设置color属性,否则颜色会不生效:
1 | |
(巨坑)模型数量太少,导致setHex(i)生成的颜色值很小,全部都接近黑色,最终渲染出来就是黑屏,让我以为渲染失败了:
1 | |
颜色值16进制,分三段,每段255,是2的8次方,16的6次方,1677216,除以166=101067
scale问题
另外会不会有缩放问题?屏幕被颜色都填充满了
看了下结构,只有最外层有scale,里面都是1,估计这个确实有问题的,得乘以什么矩阵才行
计算位置是否也要乘以矩阵才行?
1、先将模型坐标转换为世界坐标
2、缩放大小处理下
3、再传入类里面进行计算
(TODO:待整理)欧拉角和四元数的转换:
Three.js欧拉对象Euler和四元数Quaternion
果然,设置scale才行;但是不要计算scale,直接写死0.03,不然算出来的有问题,(TODO)待确认为什么有问题。
定位肯定有问题!
不对,我是将中心点转为2D,那叠加的情况岂不是就错了?
比如安全气囊被玻璃挡住了,安全气囊的中心点传入进去,得到的颜色不是纯黑的,是玻璃的颜色。
(坑)我这个场景和官方的不一样!判断逻辑得修改,我得根据拿到的id,和当前循环的id对比,看是不是同一个!
1、我算错了
2、(x)有动画动了
3、模型的定位不正确,导致我转换后错误(也不对,应该一错全部错啊)
4、(X)都是偏左上的?是不是几个位置大小不一致?
【Warning】这个方案不行,比如轮胎1,中间是空心的,就判断有误了
“轮毂盖1”又TM不在可交互的模型范围内
window.devicePixelRatio的问题
这里的x、y不对,是不是默认进来车设置了相机视角?
缺少debug工具
不能动态查看某个模型到底是什么状态
怎么搞个可以动态查看物体的调试工具?点击控制台就可以查看,类似查看DOM元素
待整理学习的几个API
this._renderer.setRenderTarget(null);
this._renderer.setRenderTarget(this._pickingTexture);
this._camera.setViewOffset()
通过离屏渲染渲染阴影
比如人物脚底随着角色移动的实时阴影,可以离屏渲染实现。
参考2022年D2论坛中,淘宝的分享内容。
(TODO)合并策略-Instanced、Merged、Naive
Instanced、Merged、Naive三种合并策略的区别:
https://threejs.org/examples/?q=instanc#webgl_instancing_performance
(TODO)原理、帧数、CPU、内存、可修改的内容
InstancedMesh
核心是减少DrawCall,减少到1。比如我们的故事森林,假如有7种树,那么就是合并成7个InstancedMesh。
矩阵相关的计算可以(缩放、旋转),顶点相关的不行。可以改颜色,也可以改材质(Three.js不行,但是Unity可以)。
压缩模型
Google的draco(天龙座)算法:
和three.js结合的一个示例:draco/README.md at master · google/draco · GitHub
GitHub - CesiumGS/gltf-pipeline: Content pipeline tools for optimizing glTF assets.
移动端帧数低于30帧
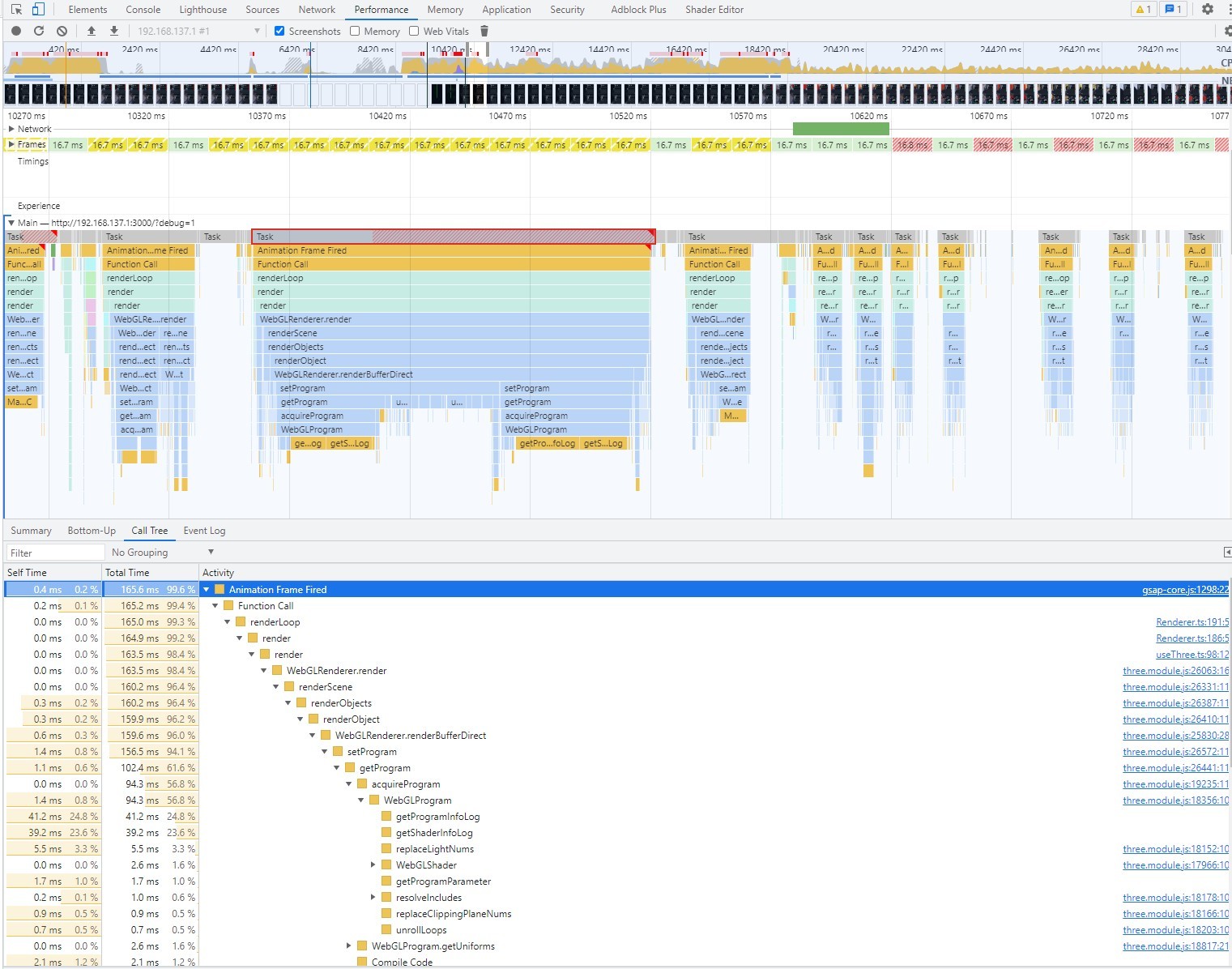
一个RAF周期的执行时间太长了(166ms),导致丢帧很严重。
需要排查下,我们在RAF中做了哪些操作、是否可以针对移动端降低这些操作的频率。
另外,我们可能可以通过分层(Layer)来大幅度提升移动端渲染性能吧?模型少了,自然面数就少了。
工具
GLTF模型分析工具:
这是一个部分开源的项目:https://github.com/donmccurdy/glTF-Report-Feedback
能看到模型的详细信息,包括GL_PRIMITIVES(几何图元)、VERTICES(顶点数)、INDICES(三角形的顶点索引数)、占用的GPU内存、动画的关键帧数量等。
从这个工具可以看到,Texture占用的GPU倍数可能达到原始文件大小的10-30倍,所以精简纹理挺重要的。
这个工具还提供在线压缩模型的功能,一个5MB的模型,通过Draco算法压缩后精简为了700KB,效果惊人。用的是google的库来实现的。
GLTF模型转换:
https://gltf-transform.donmccurdy.com/
(TODO)3D产业链的性能优化案例
这个项目性能巨差,在设计师的Mac mini上跑起来很卡顿,视觉效果也非常差。
查看网页的任务管理器,发现CPU一直属于较高的使用率状态(后来看了下,策略图也是CPU一直比较高的);再结合dev-tools的性能分析,
怀疑:是不是射线拾取一直在跑?
从耗时较长丢帧的函数调用栈来看,是渲染耗时很长,那么是因为面数多么,还是因为我们用的特效性能很差?
测试代码:
1 | |
查看下统计数据:
1 | |
对比之前策略图的统计数据:
1 | |
看起来也差不多,为什么这次产业链这个这么卡呢?
其他官方demo:
三个机器人:
1 | |
webgl_performance:
1 | |
webgl_performance_shader:
1 | |
看起来是因为三角面太多的缘故?
找了个丢帧的,发现是射线拾取大约占30ms,渲染占了70ms
渲染里面,反射占了10ms
有大约3个WebGLProgram,是不是对应2个后期处理和一个最终的渲染?
用第三方渲染器展示汽车,非常流畅
那么肯定是我们加的内容导致的卡顿,到底是什么呢?
用删除法试试?
TODOs
待尝试:
关掉镜面反射
去掉高亮
raycaster改为GPU拾取
设计师减少面数
采用其他更好的压缩算法
traverseVisible代替traverse
检查RAF中的操作,降低帧循环中的计算量(将交互、业务数据处理和RAF完全独立开),写一个RAFHelper类,参考这个文章
延迟渲染,同样参考上面这个文章,通过防抖节流实现。
合并同材质的网格
从任务管理器看,GPU耗费是很低的,CPU高一点,但是百分比也不大啊,为什么就是卡呢?
不对,GPU是很高的,应该是Chrome默认的任务管理器统计有问题,实际上看系统的任务管理器,可以看到GPU基本上占用在80%左右了;关掉这一页,GPU就回归到0了。
设计师的3080Ti测试:GPU使用率21%-25%,操控时帧数在30帧左右,GPU为什么跑不满帧数就上不去了?
(TODO)GPU到底在干嘛?为什么占用这么高?
原因1:mousemove高频触发raycaster
这是影响性能最大的因素了。
有个visible检测
另外就是改为GPU拾取。
原因2:单次mousemove耗时很长
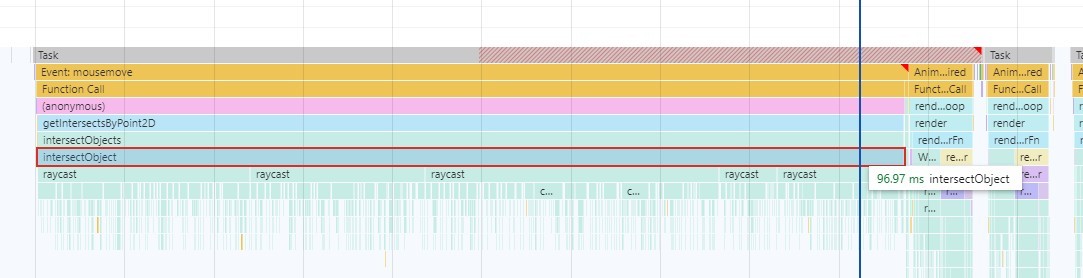
比如这就是一个mousemove事件,看到耗时接近100ms了,肯定不对。
这里有5个raycast,是不是也有问题?
原因3:多了一次默认的render
我采用了EffectComposer后,Trois默认的render没取消,因此多了一次渲染。
Trois有个onInit()可以注册生命周期函数,看起来似乎可以处理这个问题:
1 | |
但是实测发现,这个函数如果放在onMounted中注册,就太晚了;如果放在onMounted之外注册,此时renderer.value又还是空的,因此并不能用onInit()解决这个问题。
最终在onMounted中直接**重写renderFn()**解决了:
1 | |
注意,这里我踩了一个坑,就是为了性能优化,在mouseout模型时,去掉了EffectComposer里面的RenderPass,结果一不小心把默认的RenderPass也删掉了,导致鼠标只要移出模型范围,画面就不渲染了。
下面注释掉的代码,就是之前出问题的代码:
1 | |
(TODO)BVH方案
看描述,就是为了加速RayCaster的,还支持空间查询:
A BVH implementation to speed up raycasting and enable spatial queries against three.js meshes.
Casting 500 rays against an 80,000 polygon model at 60fps!
这个看起来靠谱多了,不会存在中心点透明时点不中的问题。不对,还是会有这个问题,因为中心点是我们自己主动设置的,你设置为空的坐标点,就还是会点不中的。。。。。。
但是BVH这个,可以随机选几个点作为校验点,比我们手动配置要好。因为这个可以自己配置包围盒的大小。
案例
股市森林
- 改小视锥体范围
- 替换PointLight 改为HemisphereLight, since this requires the WebGLRenderer to recompile the shader programs
- disabling AA (antialiasing) 高分辨率屏幕下差距不大
- MeshStandardMaterial改为其他材质,这个质量高,但是效率低,试试MeshLambertMaterial?
- 重用资源(geometries, materials, textures) buildForest()
- 静止状态别渲染,目前静止也有很多draw call
- 将同材质的物体改为InstancedMesh,比如装饰物,树桩等等 three.js docs
- 去除效果不明显的物体的动画
- 视锥体裁剪改为空间分割方式
- 高分辨率带来的高计算量问题
改为WebGPU不兼容- 交互改为bvh
- 计算放入Web Worker
资料
Three 之 three.js (webgl)性能优化、提高帧率的思路/方向整理:
https://blog.csdn.net/u014361280/article/details/124285654
https://blog.pig1024.me/posts/621a1fea23cc38439fdbc85d
判断性能问题,第一步都是先区分GPU还是CPU瓶颈。
提到了比如Chrome浏览器参数设置等方法:
threejs性能优化_wodomXQ的博客-CSDN博客_threejs 性能优化
three.js 性能优化的几种方法_weixin_30773135的博客-CSDN博客
three.js使用gpu选取物体并计算交点位置-木庄网络博客
(精)Three.js 拾取之GPU Picking的理解和思考_Webglzhang的博客-CSDN博客_gpu拾取
华为云官网 Web3D 和动效技术的应用与探索:
https://www.infoq.cn/article/qdtc0goyfc17uaorontz
https://attackingpixels.com/tips-tricks-optimizing-three-js-performance/
https://discoverthreejs.com/tips-and-tricks/
https://discourse.threejs.org/t/how-can-i-optimise-my-three-js-rendering/42251
破案了,是Pass的问题
EffectComposer哪怕只加一个基础的Pass,也会很卡:
1 | |
改为延迟触发高亮 + 动态加减Pass来进行优化试试。
TODOs
instance实例化创建
React Fiber的优化经验
reqeuestIdleCallback
延迟渲染
分层:3D tiles,Cesium一层场景,BBL二层场景,分宏观微观采用不同的技术
千万级渲染
如果要渲染1000W的数据,你如何做技术选型、如何优化性能?
1、【数据】数据预处理,布局预计算,服务端,静态化
2、【调度】fiber架构,不卡住主线程
3、【CPU】web worker,不卡住渲染线程
4、【??】增量渲染、局部擦除
5、【CPU??】减少drawcall
6、【交互】缩略图,局部显示的方式
7、【GPU】将计算做并行拆解,放入GPU中用Shader处理
8、WebGPU(Electron打包,下一个版本的Electron估计就会嵌入Chrome113版本了,默认支持WebGPU)
附录
手机GPU天梯榜
我的手机是红米K30Pro,高通骁龙865,刚好是参考基准,分值100分。
iPhoneXR是A12,96.5分。
iPhone6是A8,11.6分。
iPhone13是A15,200分。
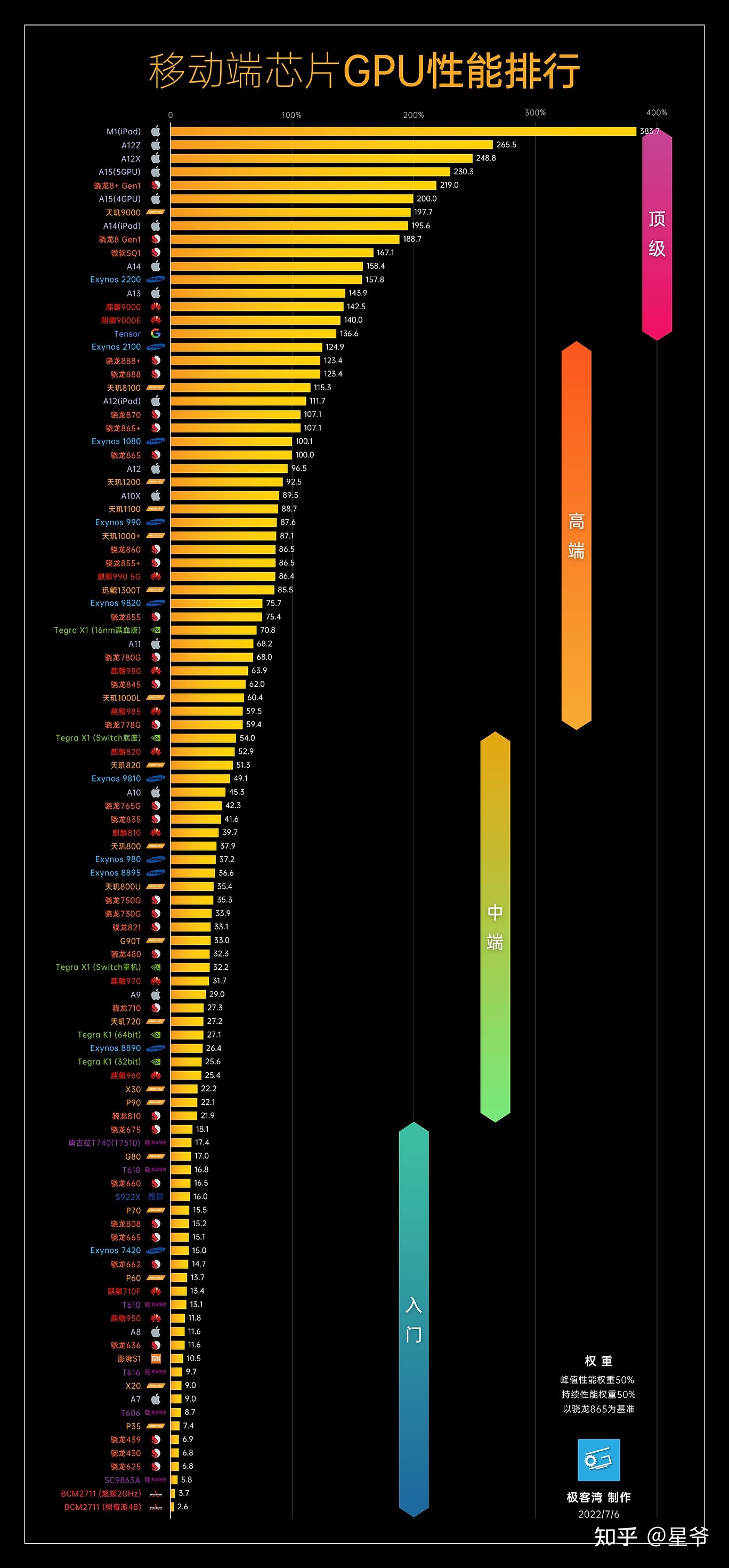
手机GPU和PC的显卡几乎没有技术差距,性能表现差距是面积功耗成本不同导致的。