HPA学习笔记
我们通过kubernetes的弹性伸缩(HPA, Horizontal Pod Autoscaler)来动态控制线上docker资源,以从资源角度来解决大批量生成视频的问题(比如个股收盘解读的性能问题)。目前云平台已经提供了HPA的支持,需要我们开发自定义指标操控功能,可以控制什么时候开启HPA、扩容多少、什么时候关闭HPA。
参考文档:http://172.20.1.247/wiki/index.php/K8s:%E5%BC%B9%E6%80%A7%E4%BC%B8%E7%BC%A9%E4%BD%BF%E7%94%A8
名词概念
Raw values
原始值,应该是docker预设的CPU、内存、硬盘等大小。
Utilization values
使用值,当前真正的使用率。
Object Metrics
External Metrics
Metrics的API
metrics.k8s.io
custom.metrics.k8s.io
external.metrics.k8s.io
Kubernetes objects
type
name
namespace
/namespace/object-type/object-name/metric-name?labelSelector=foo
For example, to retrieve the custom metric “hits-per-second” for all ingress objects matching “app=frontend` in the namespaces “webapp”, the request might look like:
1 | |
从API的命名来看,我们如果想要实现custom metrics,应该是要先在K8S集群上申请这几个内容的:namespace、object(包含type和name)、metric(包含name)、labelSelector
另外还有权限认证也是需要申请的。
label selector
sub resource
容器状态
ready
in use
deletion
missing metrics
set aside
discarded
我们设置自定义metrics的时候,也要注意下状态问题。
Prometheus的四种Metric Type
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/promql/prometheus-metrics-types
常用命令行指令
列出HPA:
1 | |
查看详细信息:
1 | |
删除自动扩容:
1 | |
创建HPA:
1 | |
It will create an autoscaler for replication set foo, with target CPU utilization set to 80% and the number of replicas between 2 and 5. The detailed documentation of kubectl autoscale can be found here.
常用API
副本数量的算法
From the most basic perspective, the Horizontal Pod Autoscaler controller operates on the ratio between desired metric value and current metric value:
1 | |
Custom Metrics
K8S 1.6版本增加了对custom metrics的API支持:
可以通过Object类型的metric实现自定义控制功能,具体可以看下这个文档中的“Example”的示例。
请求的URL类似这样:
1 | |
这是custom metrics的API文档:
Java版的Prometheus EndPoint
SpringBoot里面可以通过Spring Boot Actuator很简单的实现,参考这个文章:
https://tanzu.vmware.com/developer/guides/spring/spring-prometheus/
其他参考资料:
https://prometheus.io/docs/instrumenting/clientlibs/
https://github.com/prometheus/client_java
几个问题
云平台怎么确定采集指标的地址?
容器登记的时候,可以暴露指标,只要符合Prometheus的规范即可;然后在云平台就可以选择和使用这个指标了。
可以咨询下徐新康这边的潘灵辉,他们也是Java写的,用过这一套。
云平台Prometheus和Prometheus Adapter已经部署好了,我们只需要提供接口即可,开发量不大。
如何鉴权
因为容器都是跑在公司的统一云平台上的,因此没有鉴权。
HPA容器如何解决依赖服务的IP类鉴权问题
比如S3,他们可能限制了IP,怎么处理?
还有数据库,要加入100个IP么?
开发流程
- 开发Prometheus的Gauge类型的Metric接口
- 在云平台登记自定义的指标
- 在云平台申请HPA的容器
- 给HPA容器设置动态扩容的规则
- 当有大批量生成任务过来时,调整metrics接口,设置返回的指标值
1 | |
假如我们在云平台登记的指标值是1,即代表1个容器实例,而我们要在30分钟内生成100个股收评,单个生成时间是700秒(4C4G),那么我们总共需要的容器数量是:100 * 700 / 3600 = 19.44个容器,向上取整就是20个容器,那么我们就把metrics接口的当前指标值设置为20即可(实际算法应该更大一些,因为要考虑到不是刚好能在30分钟结束的时候终止生成进程):
1 | |
等处理结束后,我们再将这个值调小到默认的初始值2.
另外提供指标的应用需要是咨询了云平台同事,现在不用修改了。有状态应用部署,因此我们还得修改下应用的设置。
无状态工作负载:实例完全独立,功能相同,支持弹性伸缩、滚动升级
有状态工作负载:实例具有持久化的存储,支持有序的命名、部署,比如MySQL-HA、图数据库
程序执行流程
可以参考这个流程图:
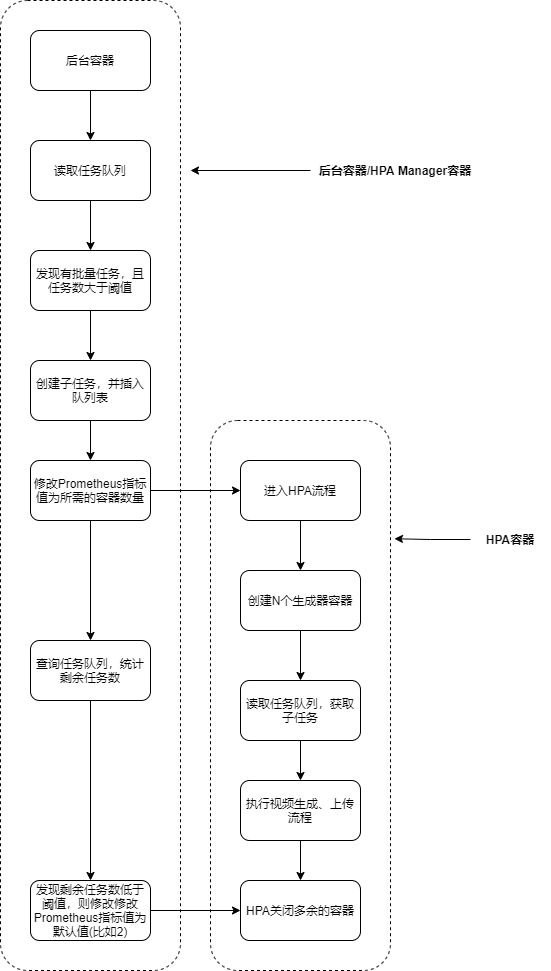
注意事项
容器被强制半途干掉的问题
如果选择了系统指标,比如CPU、内存之类的,那么缩容的时候要注意,可能会在你程序跑一半的情况下把容器干掉。
如果选择自定义指标,则没有这个问题。
固定IP需要设置为HPA上限的1.25倍
比如HPA上限100个容器,那么IP就需要设置为125个,不然滚动更新不了。
待解决的问题
过程文件如何存储?
HAP缩容后,容器就下掉了,那么中间生成的过程数据就没了,不利于我们排查问题。
陈龙这边在做分布式存储方案ceph,但是目前线上部署的资源不多,还不足以应对我们的大批量需求(我们这个单个视频大约有1G的过程数据,如果按照盘后给3000+股票生成,那么就是3000G / 30 / 60 = 1.67G/s)。
如果按照盘后30分钟生成100个热点股票来算,那么 100 * 1024 / 30 / 60 = 57M/s,还行。
但是这些数据写入,是走的网络,不是本地硬盘,耗时也是比较久的,对于我们的生成性能会有影响。
另外日志尽量考虑记入ELK,走林挺这边。
参考资料
官方介绍原理的文档:
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#
SpringBoot+HPA(这个不是通过Java操控HPA,只是搭建了一个测试HPA的Demo而已):
https://piotrminkowski.com/2020/11/05/spring-boot-autoscaling-on-kubernetes/
https://github.com/learnk8s/spring-boot-k8s-hpa
K8S Prometheus Adapter:
https://github.com/DirectXMan12/k8s-prometheus-adapter/blob/master/docs/walkthrough.md