动态视频自动生成方案
竞品
数可视
https://hanabi.data-viz.cn/index?lang=zh-CN
镝数图表
https://dycharts.com/appv2/#/pages/home/index
巨量创意
flourish
https://flourish.studio/examples/
方案
服务端生成
canvas动画和截图在服务器端运行,后端根据标识获取截图
利用FFmpeg将图片合并成视频,并将视频存储在server端,并返回相应下载url
前端通过请求得到视频文件
网页截屏生成视频
用了这个工具:
https://github.com/tungs/timecut#node-install
可以通过launchArguments添加Puppeteer的启动参数
可以通过inputOptions、outputOptions添加FFmpeg的输入输出参数
如何在打开的网页中执行JS脚本?
比如网页在出现id=screen的元素后,才标志加载完成,因此我需要获取页面上有没有这个元素,再确定要不要开始截屏。
可以通过preparePage((page) => {})方法在截屏前执行JS脚本:
1 | |
具体操作页面元素,是通过page这个参数(Puppeteer实例对象)进行的,文档详见:
https://github.com/puppeteer/puppeteer/blob/main/docs/api.md#class-page
合并视频和音频
自己搭建语音合成服务
https://github.com/webfansplz/volute
用了树莓派+科大讯飞的API
通过ffmpeg来实现。
PS:这个工具我学好了,自己今后也有很多场景可以用到。
官方文档:
http://ffmpeg.org/documentation.html
timecut中可以通过inputOptions配置项来添加ffmpeg参数,合并音频。[‘-framerate’, ‘30’]
命令示例
将N张图片合并成视频:
1 | |
合并视频和音频:
1 | |
在指定时间点插入音频
在-filter_complex中指定延迟数据,并将滤镜进行重命名,然后通过-map确定要把哪些内容合并到最终的视频里面去,类似这样:
1 | |
我之前给滤镜重命名了,但是没有通过-map参数指定需要合并的内容,会报如下的错误:
1 | |
也可以不给滤镜指定别名,这样就不用添加-map,默认把所有的都合并到一起:
1 | |
如果有更加复杂的滤镜操作,也可以这样设置:
1 | |
上面这个命令就是先把6个音频延时拼接合并好,然后再合并音频和视频。
在指定位置插入多个音频
1 | |
设置音量
https://blog.csdn.net/LS7011846/article/details/90813220
查看音频音量:
1 | |
根据倍数设置音量(注意输入输出文件名不能是同一个):
1 | |
(TODO)让声音在结束时变小消失
截取指定时间区间的音频
1 | |
合并视频
官方文档:https://trac.ffmpeg.org/wiki/Concatenate
overlay是叠加,concat是拼接。
拼接可以参考这个文章:
https://stackoverflow.com/questions/7333232/how-to-concatenate-two-mp4-files-using-ffmpeg
https://www.jianshu.com/p/a9bccc12229b
由于我们用到了filter,因此我们应该用concat video filter来拼接视频;不过这个方法似乎并不好(这是有损压缩,且要求分辨率和帧率一致),别人是将这个作为备选方案的。
1 | |
直接以文件格式拼接
要求编码、容器格式相同,且需要是MPEG格式,我试了下mp4的是不行的:
1 | |
FFmpeg concat 分离器
创建一个filelist.txt文件,存储需要concat的文件列表:
1 | |
然后执行合并命令:
1 | |
这个我试了下可行,前提也是视频要保证是相同码率、分辨率和大小的。
队列机制
考虑到生成耗时较长,不可能前端发送请求一直等着,因此需要有个队列机制,且前端异步请求进度,获取最终的生成结果。
质量
为什么新华智云的这么清晰?
SVG替代Canvas和DOM,矢量放大录制?
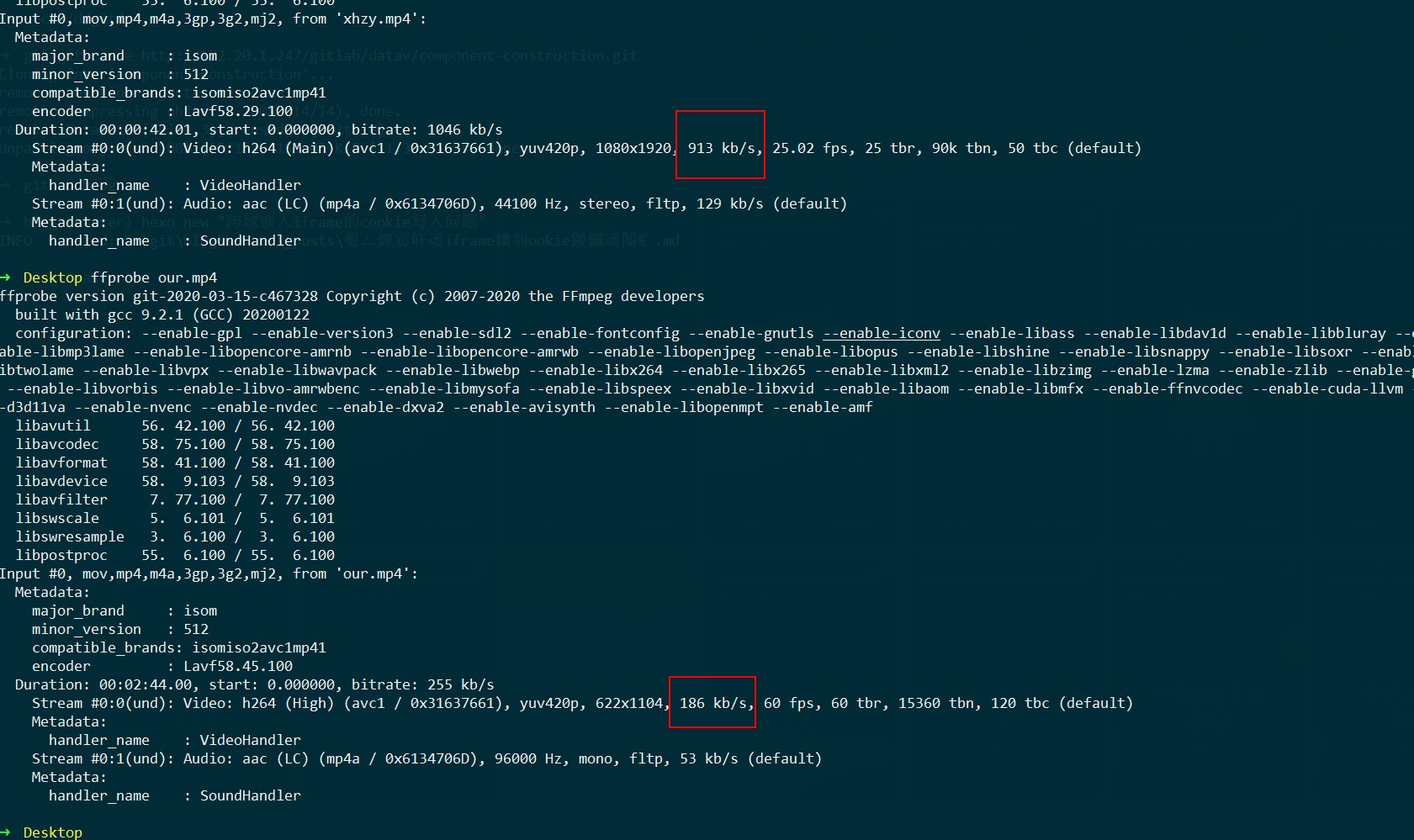
上面是新华智云的,下面是我们自己生成的,可以看到他们码率比我们高很多,帧数比我们低很多,因为他们没有太多动画元素,所以帧数低点也没关系。
另外他们的分辨率比我们大。
今日测试的数据:
生成时间267秒
5M
17秒
需要反推的视频:
视频时长:156秒
9.2倍
41分钟
46M
改进策略
按照大分辨率制作原始网页
尝试通过这种方式解决Canvas图像清晰度不够的问题。
Canvas不像SVG,放大录制没效果。
性能
和蜻蜓点金的对比:
1 | |
算4分钟一个
4000只股票,16000分钟
100个docker也要160分钟,接近3小时,太慢了
如果按照30分钟内生成4000只股票的收评来反推,要533个docker?不可能!

蜻蜓点睛2020.12.11日数据:
截止15:13,28个自选股中有8个有当日的收盘解读了。
截止15:30,28个自选股中有23个有当日的收盘解读了。
一些录屏方案
琢磨下这个Chrome插件是怎么实现的:https://github.com/alyssaxuu/screenity
稳定性
通用数据处理方案
可以参考结果页的数据处理方式,然后结合模板引擎。
比如我们将常用数据提前拿过来放到数据库,或者前端直接传入问句。
针对字幕
通过模板字符串匹配数据:
1 | |
针对页面
每个页面设置好数据源和请求参数。
以问财问句为例:
1 | |
一些问题
技术选型:SVG还是Canvas?
在D3Charts基础上添加还是单独写一个新的库?
稳定性问题
缺少一张图片是否就会导致合并失败?
是的。
这个不管是分页还是跳帧,都会遇到这个问题,因此目前解决稳定性的关键就是如何保证每一帧都能成功截取。
方案一:想办法保证每一帧都能成功截取
方案二:自动补帧(通过timesnap的frameProcessor配置项实现,将上一帧的内容复制为本帧的内容):
1 | |
可以设置一个策略:当连续出现N帧失败时,就判断为出现严重异常,画面无法连续了,直接reject中断截图,并发送通知让用户进行排查(可以通过总帧数和当前帧数,算出是哪个时间点出问题了)。
性能问题
FFmpeg的合成是很快的,主要的性能问题在timecut截屏这一块。
以60帧,30秒时长的视频为例,需要用无头浏览器截取1800张图片,大约需要500秒,基本上录制时间是实际时间的17倍。
试试这个参数:
1 | |
静止的页面,用一张图代替截屏
更多的测试数据
视频的生成时间,受视频总时长、帧数、服务器资源等的影响。
这里做了2个测试:
1 | |
1 | |
后续正式投入使用,性能上是可以大幅度优化的,比如:
针对单个视频的加速:
如果视频较长,可以对视频进行分段,拆分为N个动态网页,同时进行录制,这样可以将生成时间缩减到原来的N分之一。
针对多个视频的加速:
如果同时有多个视频生成,可以通过增加服务器资源的方式来提升效率,比如同时开启多个进程生成视频。
2020.10.26:
scale=2,11秒的视频,花了210秒生成,比例约为20倍;gif动画我们放慢到了20分之一
用jpeg替代png
从17秒缩短到14秒
使用pipeMode
并没有什么提升。
using canvas-capture mode
这个只能针对canvas画的内容,据说性能会高非常多,能将时间缩短到原来的八分之一。
run with headless mode off
会调起Chrome浏览器,有问题。
enable GPU acceleration
(e.g. --use-gl=desktop)
use Chrome instead of Chromium
using the executablePath configuration
(TODO)拆分视频录制时间点
1 | |
发现timesnap有这么一个配置:shouldSkipFrame
1 | |
这个可以将一个视频按不同时间点进行拆分,但是怎么合并呢?
测试数据
针对第三页进行测试,总共需要截取690张图片。
1、整页截取时长:211.421秒
2、只截取余数为1的帧数:28.222秒
因为实际程序首尾还有一些其他逻辑,所以从这个数据来看,基本上是成比例的。
现在剩下的问题,就是这个帧数拆分准不准(虚拟时间准不准)?会不会不同的进程,碰巧截取的图片是重合的?
这个感觉肯定对不准,因为每个进程截屏的起点时间,并不是相同的。
另外通过图片合成视频有个问题:只要缺少一个图片,就无法合成了。
然后我用整个页面做了下测试:
需要截取的帧数:10110,视频时长168秒
耗时460秒,单从这个数据来看,接近3倍,还是可以的,但是只成功了3000多张图片,其他全部崩掉了。
为什么后面的会崩掉呢?因为页面报错画不出来了。。。
临时修改为其他的网页进行测试,没有采用scale放大,5个进程
需要截取的帧数:10110,视频时长168秒
耗时645秒,倍率为3.84;扣除合成的大约20秒,耗时625秒,倍率3.72
关键在于这次没有失败的截图!
2020.11.10:
我改回正式的页面地址进行测试,起5个进程,发现168秒视频花费了2937秒,而且部分图片失败了,只有10050张图片,不对劲。
10050张图片,642秒,失败了一张图片
优化Puppeteer
https://juejin.im/post/6844903849086582798
(精)拆分页面,并行录制
比如页面支持传入page参数,直接从某一个页面开始播放;然后后端解析配置文件,给每个页面分配一个子进程,并行录制视频,录制完成后再将其合成为一个视频。
目前设置scale=2,18个页面,视频总时长172秒,10个进程跑,共耗时471秒(其中可能还有失败了自动重跑的情况),耗时比1:2.74。
跳帧方式的闪烁问题
通过跳帧的方式,多进程截取图片,然后合成视频时,发现在每个页面切换的时候,视频会出现闪烁的情况。
怀疑是多进程截屏,第一帧的起点计算时机不一致导致的。
想要解决这个问题,就要弄清楚puppeteer的截屏机制:到底是什么时候开始截屏的?
查看timesnap的源码,发现在操作puppeteer的过程中,是这样的一个流程:
- 启动puppeteer(launch)
1 | |
- 打开新页面
1 | |
- 执行初始操作(队列阻塞帧的执行、重写JS的一些时间函数等)
注意,到这里,都还没打开我们的目标网页,只是启动无头浏览器并进行一些浏览器相关的设置而已。
- 打开目标网页
1 | |
- 网页加载完成,并执行前置钩子脚本
1 | |
如果有前置暂停(startWaitMs),则暂定一下
开始计算截屏帧数等相关数据
估计就是这一步出问题了,这一步计算量较大,有不少for循环,耗时不定(总帧数、当前的CPU资源使用情况等,都可能导致这一段计算耗费的时间存在差异),可能导致多进程帧数错乱。
由于前置的这些操作,可能不同进程耗费的时间不一样,这样就无法确保每个进程的截屏起点是同一个时间点,因此难以保证相邻两帧的顺序。
发现timesnap有这么一个配置项:config.startDelay,那是否可以统一延迟一段时间再截屏?也不行,因为页面已经在播放了。
找到几个puppeteer的配置项:page.waitForSelector、page.evaluate;尝试用这个来替代我之前的setInterval判断作图元素是否存在,然后发现生成的视频还是有闪烁。
现在看来,就只有分页截屏这一个方法了。
为什么生成的视频会模糊?
结论放最前面:
1、图片格式采用png
2、适当放大高宽
3、少用灰色和红色、橘黄色等(这些颜色有何特性?)
我发现字幕是很清晰的,模糊的是带有颜色的图表和图表中的文字。
似乎和字体类型、颜色关联很大,比如白色宋体的就比较清晰。
这个和是否在docker中,关联不大,我用Node+本地笔记本生成的视频,也是存在模糊的情况的。
这个和合并也没啥关系,因为我看生成的原始图片中,就是会模糊一些的。
但是直接网页展示的时候,是很清晰的,那么问题就出在puppeteer截屏这里了。
为什么puppeteer截屏会模糊呢?
jpeg改为png
有所改善,png下,对于鲜艳的颜色,会显示得比较好(感觉应该和透明度有关系,png相比jpeg,多了透明度信息),比如黄色背景中的白色文字,色彩渗透会少很多。
这是jpeg:
这是png:
(TODO)调整puppeteer配置项
(TODO)最低的不影响清晰度的帧数是多少?
因为我们的截屏是截取的静态帧,不是电影这种模糊帧,因此24帧在动画连贯性的表现上,是远远不够的。
帧数如果设置过高,会影响性能,我们需要找到一个均衡点。
虽说理论上24帧就可以了,但是这个实际上是跟页面的动态内容相关的。
我设置30帧,发现流畅度上面还是能看出有点问题的;设置为40帧,基本就感觉不出来了。
另外我发现:
1、puppeteer没有帧数上限,比如我设置帧数为2000也是可以正常截屏的,但是合并生成的视频会有问题,感觉ffmpeg合并是有个上限的;
2、帧数对于最终生成的视频的文件大小,影响并不大。比如30帧生成的视频有2210KB,200帧生成的视频也就3658KB,文件大小并不是成倍增大的。
参考文章:为什么电影24帧就算流畅,主机30帧就算流畅,而电脑游戏需要60帧流畅?
1 | |
滤镜
https://blog.csdn.net/tkp2014/article/details/53310285
通过
-filter-complex的表达式功能,可以将多个滤镜组装成一个调用图,实现更为复杂的视频剪辑。
https://cloud.tencent.com/developer/article/1505973
往前走
自动匹配组件
根据数据的特性和格式,自动给出可匹配的可视化组件
接入问财文本解析
问财解析文本,生成上一步的数据,然后就可以自动匹配生成静态页面效果,然后调整下顺序和动画,就能生成视频了
动态图表技术
https://github.com/vega/vega-lite
参考资料
技术
(精)NLP搜索视频(可用于我们的视频质检):
https://github.com/haltakov/natural-language-youtube-search
动画库的技术选型:
https://css-tricks.com/comparison-animation-technologies/
FFmpeg中文文档:
https://www.bookstack.cn/read/other-doc-cn-ffmpeg/README.md
FFmpeg的命令行封装库:
https://github.com/yuanqing/vdx
别人已经在搞了(研究下新华智云的积木平台,以及中信建投证券的“蜻蜓点金”APP):
服务端生成视频:
https://www.jb51.net/html5/678376.html
前端导出视频和gif:
https://segmentfault.com/q/1010000022153818
前端截图上传后端生成视频:
https://developer.51cto.com/art/201704/536392.htm
一些短视频的Demo(来自梅老板):
https://zxjtdsp.csc108.com/app/zxjt/detail/d6409cac7560ab97aac112c4171e7b033bfd1d78
https://zxjtdsp.csc108.com/app/zxjt/detail/af737c5cd12f8a664a767d2a2152b6a62ca7235e
Magic短视频智能生成平台:
https://magic.shuwen.com/?spm=xinhuazhiyun.home.0.1.2new6u
FFmpeg常用操作:
https://www.cnblogs.com/gccbuaa/p/6800446.html
下载mp3音乐文件:
http://www.9ku.com/qingyinyue/chunyinyue.htm
优秀的品质感
https://www.youtube.com/watch?v=vj6RVg56LSs&list=PLHFlHpPjgk72JW5vfYlzycSgG_Z6EV4hK&index=19
背景音乐下载
YouTube上没有版权保护的背景音乐下载: